This article is not original content; it is modified based on original work, aimed at sharing knowledge and learning exchange. Since I cannot determine who the original author is, I apologize if this infringes on your rights; please contact me for removal.


When facing a large C/C++ program from someone, we can evaluate the programmer’s experience and level just by looking at their use of struct. Because a large C/C++ program inevitably involves some (even a lot) of structures for data combination, these structures can combine data that originally belongs to a whole. To some extent, whether one knows how to use struct and how to use struct is a hallmark of whether a developer has rich development experience. In network protocols, communication control, and embedded systems C/C++ programming, we often need to transmit not just simple byte streams (char type arrays), but a whole composed of various data, represented as a structure.
Inexperienced developers often save all the content to be transmitted in a char array in order, using pointer offset methods to transmit network messages and other information. This makes programming complex, prone to errors, and once the control method and communication protocol change, the program requires very detailed modifications.
An experienced developer flexibly uses structures. For example, suppose the network or control protocol requires the transmission of three types of packets, with formats respectively as packetA, packetB, packetC:
struct structA
{
int a;
char b;
};
struct structB
{
char a;
short b;
};
struct structC
{
int a;
char b;
float c;
}
For an excellent developer, the transmission of packets is designed as follows:
struct CommuPacket
{
int iPacketType; // Packet type flag
union // Each transmission is one of the three packets, using union
{
struct structA packetA; struct structB packetB;
struct structC packetC;
}
};
During packet transmission, the entire struct CommuPacket is directly transmitted. Suppose the prototype of the sending function is as follows:
/* pSendData: Address of the byte stream to send, iLen: Length to send */
Send(char * pSendData, unsigned int iLen);
The sender can directly call to send an instance of struct CommuPacket sendCommuPacket:
Send( (char *)&sendCommuPacket , sizeof(CommuPacket) );
Suppose the prototype of the receiving function is as follows:
// pRecvData: Address of the byte stream to send, iLen: Length to receive
// Return value: Actual number of bytes received
unsigned int Recv(char * pRecvData, unsigned int iLen);
The receiver can directly call to save the received data in an instance of struct CommuPacket recvCommuPacket:
Recv( (char *)&recvCommuPacket , sizeof(CommuPacket) );
Next, judge the packet type for corresponding processing:
switch(recvCommuPacket.iPacketType)
{
case PACKET_A:
… // A type packet processing
break;
case PACKET_B:
… // B type packet processing
break;
case PACKET_C:
… // C type packet processing
break;
}
What is most noteworthy in the above program is:
Send( (char *)&sendCommuPacket , sizeof(CommuPacket) );
Recv( (char *)&recvCommuPacket , sizeof(CommuPacket) );
The forced type conversion: (char *)&sendCommuPacket, (char *)&recvCommuPacket, first taking the address, then converting to char type pointer, so that we can directly use the function that processes byte streams. Using this forced type conversion, we can also facilitate program writing, for example, to initialize the memory where sendCommuPacket resides to 0, we can call the standard library function memset() like this:
memset((char *)&sendCommuPacket, 0, sizeof(CommuPacket));
#include <iostream>
#pragma pack(8)
using namespace std;
struct example1
{
short a;
long b;
};
struct example2
{
char c;
example1 struct1;
short e;
};
#pragma pack()
int main(int argc, char* argv[])
{
example2 struct2;
cout << sizeof(example1) << endl;
cout << sizeof(example2) << endl;
cout << (unsigned int)(&struct2.struct1) - (unsigned int)(&struct2) << endl;
return 0;
}
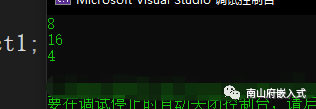
What is the input result of the program?
The answer is: 8 16 4
Natural alignment is the default alignment method, which aligns according to the largest member size in the structure.For example:
struct naturalalign
{
char a;
short b;
char c;
};
In the above structure, the largest size is short, which is 2 bytes, so the char members a and c in the structure are aligned to 2. The result of sizeof(naturalalign) is 6 (the structure alignment is determined by the largest size);
If changed to:
struct naturalalign
{
char a;
int b;
char c;
};
The result above is obviously 12, not 6. Let’s see, char is one byte, int is 4 bytes, so the largest in the structure is int b, so the alignment is calculated in 4-byte units. Therefore, even though char a is one byte, it still requires a 4-byte space.
Generally, the default alignment conditions can be changed using the following methods:Use the pseudo-instruction #pragma pack (n), and the compiler will align according to n bytes; · Use the pseudo-instruction #pragma pack (), to cancel the custom byte alignment.
Note:If the n specified in #pragma pack (n) is greater than the size of the largest member in the structure, it will not take effect; the structure will still align according to the size of the largest member.
For example:
#pragma pack (n)
struct naturalalign
{
char a;
int b;
char c;
};
#pragma pack ()
When n is 4, 8, or 16, the alignment method is the same, and the result of sizeof(naturalalign) is 12. However, when n is 2, it takes effect, making the result of sizeof(naturalalign) equal to 6.
Additionally, using __attribute((aligned (n))) can also align the structure members on n-byte boundaries.
For example, defining struct class and class class:
struct structA
{
char a;
…
}
class classB
{
char a;
…
}
then:
structA a;
a.a = 'a'; // Access public member, valid
classB b;
b.a = 'a'; // Access private member, invalid
Many documents state that this has given the full difference between struct and class in C++, but in fact, there is another point that needs attention: Struct in C++ maintains full compatibility with struct in C (which aligns with C++’s original intention—“a better C”), therefore, the following operations are legal:
// Define struct
struct structA
{
char a;
char b;
int c;
};
structA a = {'a' , 'a' ,1}; // Directly assign initial values during definition
That is, struct can be directly assigned initial values to its member variables using { } when defined, while class cannot. In the classic book “Thinking C++ 2nd Edition,” the author emphasizes this point.
#include <iostream>
using namespace std;
struct structA
{
int iMember;
char* cMember;
};
int main(int argc, char* argv[])
{
structA instant1, instant2;
char c = 'a';
instant1.iMember = 1;
instant1.cMember = &c;
instant2 = instant1;
cout << *(instant1.cMember) << endl;
*(instant2.cMember) = 'b';
cout << *(instant1.cMember) << endl;
return 0;
}
The output order of the above result is: a,b;
Why is this? Because in line 16, the modification of instant2 changes the value in instant1!
The reason is that the assignment statement instant2 = instant1 in line 14 uses variable-by-variable copying, which makes the cMember in both instant1 and instant2 point to the same memory, hence the modification of instant2 also modifies instant1.
END
This article is reprinted from the WeChat public account “Xiao Nan Microcontroller”. Copyright belongs to the original author. If there is any infringement, please contact for deletion.
→ Follow for more updates ←