2.2 Fundamentals of Language Processors
A language processor is a type of system software that translates programs written in high-level languages or assembly languages into machine language programs so that they can run on computers. Language processors are mainly divided into three basic types: assemblers, compilers, and interpreters.
2.2.1 Basic Principles of Assemblers
1. Assembly Language
Assembly language is a machine-oriented symbolic programming language designed for a specific computer. Programs written in assembly language are called assembly language source programs. Since computers cannot directly recognize and execute symbolic language programs, a special translation program called an assembler is used for translation. Writing programs in assembly language must follow the specifications and conventions of the language used.
Assembly language source programs consist of several statements, which can be divided into three categories: instruction statements, pseudo-instruction statements, and macro-instruction statements.
(1) Instruction Statements. Instruction statements, also known as machine instruction statements, generate corresponding machine code after assembly, which can be directly recognized and executed by the CPU. Basic instructions include ADD, SUB, AND, etc. When writing instruction statements, the format requirements of the instructions must be followed. Instruction statements can be classified into transfer instructions, arithmetic operation instructions, logical operation instructions, shift instructions, transfer instructions, and processor control instructions.
(2) Pseudo-instruction Statements. Pseudo-instruction statements instruct the assembler to perform certain tasks during the assembly of the source program, such as allocating storage unit addresses for variables or assigning values to symbols. The difference between pseudo-instruction statements and instruction statements is that pseudo-instruction statements do not generate machine code after assembly, while instruction statements do. Additionally, the operations indicated by pseudo-instruction statements are completed during the assembly of the source program, while the operations of instruction statements must be completed during the program’s execution.
(3) Macro-instruction Statements. In assembly language, users can define program segments that are used repeatedly as macros. The definition of a macro must follow specific regulations, and each macro has a corresponding macro name. Whenever this segment of code is needed, the macro name can be used at the appropriate position, which is equivalent to using that segment of code. Therefore, macro-instruction statements are references to macros.
2. Assembler
The function of an assembler is to translate source programs written in assembly language into machine instruction programs. The basic tasks of an assembler include converting each executable assembly statement into the corresponding machine instruction and processing pseudo-instructions that appear in the source program. Since the part of the assembly instruction that forms the operand address may reference symbols that are defined later, assemblers generally need to scan the source program twice to complete the translation process.
The main task of the first scan is to define the values of symbols and create a symbol table ST, which records the values of symbols encountered during the assembly. Additionally, there is a fixed machine instruction table MOT1, which records the mnemonic and length of each machine instruction. During the translation of the source program by the assembler, to calculate the address of each assembly statement label, a location counter (LC) is established, which generally starts at 0. During the scanning of the source program, each time a machine instruction or a pseudo-instruction related to memory allocation (such as defining constant statements or defining storage statements) is processed, the value of LC increases by the corresponding length. Thus, during assembly, the content of LC is the offset address of the next instruction to be assembled. If the statement being assembled is labeled, the value of that label is taken from the current value of LC.
Furthermore, during the first scan, pseudo-instructions related to defining symbol values also need to be processed. For convenience, a pseudo-instruction table POT1 can be established. Each element of the POT1 table has only two fields: the mnemonic of the pseudo-instruction and the corresponding subroutine entry. The steps (1) to (5) describe the process of the assembler’s first scan of the source program.
(1) Set the initial value of the location counter LC to 0. (2) Open the source program file. (3) Read the first statement from the source program. (4) while (the current statement is not END statement) { if (the current statement has a label) then fill the label and the current value of the location counter LC into the symbol table ST; if (the current statement is an executable assembly instruction statement) then look up the MOT1 table to get the length K of the current instruction and set LC = LC + K; if (the current instruction is a pseudo-instruction) then look up the POT1 table and call the corresponding subroutine; if (the current instruction's opcode is an illegal mnemonic) then call the error handling subroutine. Read the next statement from the source program; } (5) Close the source program file.The task of the second scan is to generate the target program. In addition to using the symbol table ST generated from the previous scan, the machine instruction table MOT2 is also used, which contains elements such as machine instruction mnemonics, binary operation codes, format, and length. Additionally, a pseudo-instruction table POT2 is set up for use during the second scan. Each element of POT2 still has two fields: the mnemonic of the pseudo-instruction and the corresponding subroutine entry. The difference from the first scan is that pseudo-instructions have completely different handling during the second scan.
During the second scan, executable assembly statements should be translated into corresponding binary code machine instructions. This process involves two aspects: one is converting the machine instruction mnemonics into binary machine instruction operation codes, which can be achieved by looking up the MOT2 table; the other is determining the values of operands in the operand area (in binary representation). Based on this, machine instructions represented in binary code can be assembled.
2.2.2 Basic Principles of Compilers
1. Overview of the Compilation Process
The function of a compiler is to translate source programs written in a high-level language into equivalent target programs (assembly language or machine language). The working process of a compiler can be divided into six stages, as shown in the diagram below, and in actual compilers, some of these stages may be combined for processing.
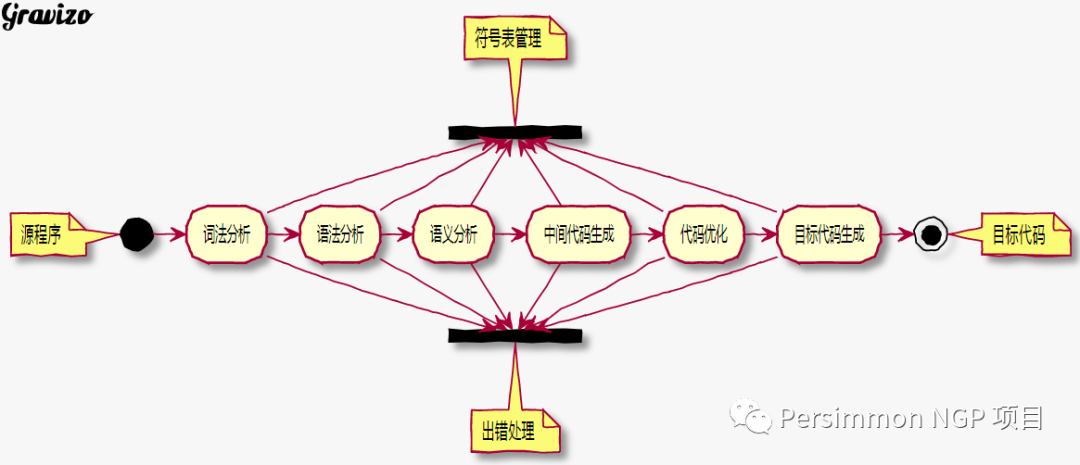
Below is a brief introduction to the main functions implemented at each stage.
1) Lexical Analysis
The source program can be simply regarded as a multi-line string. The lexical analysis phase is the first stage of the compilation process, and its task is to scan the source program from front to back (left to right), identifying individual “word” symbols. A “word” symbol is the basic syntactic unit of programming languages, such as keywords (also known as reserved words), identifiers, constants, operators, and delimiters (such as punctuation marks, left and right parentheses). The output of the lexical analysis program is often in the form of pairs, i.e., the type of the word and the value of the word itself.
2) Syntax Analysis
The task of syntax analysis is to decompose the sequence of word symbols into various syntactic units, such as “expressions,” “statements,” and “programs,” based on the syntactic rules of the language. The syntactic rules are the construction rules of various syntactic units. Through syntax analysis, it is determined whether the entire input string constitutes a syntactically correct program. If there are no syntax errors in the source program, syntax analysis can correctly construct its syntax tree; otherwise, it points out syntax errors and provides corresponding diagnostic information.
Lexical analysis and syntax analysis are essentially analyses of the structure of the source program.
3) Semantic Analysis
The semantic analysis phase analyzes the meaning of each syntactic structure, checks whether the source program contains static semantic errors, and collects type information for use in the subsequent code generation phase. Only source programs that are correct in both syntax and semantics can be translated into correct target code.
One of the main tasks of semantic analysis is type analysis and checking. A data type in programming languages generally contains two aspects: the carrier of the type and the operations on it. For example, the integer division operator can only operate on integer data; if there are floating-point numbers among its operands, it is considered a type mismatch error.
4) Intermediate Code Generation
The task of the intermediate code generation phase is to generate intermediate code based on the output of semantic analysis. “Intermediate code” is a simple and clearly defined notation system that can take several forms, all of which share the common feature of being machine-independent. The most commonly used form of intermediate code is three-address code, which is very similar to assembly language instructions and is often implemented using quaternions. The form of a quaternion is: (operator, operand1, operand2, result).
Semantic analysis and intermediate code generation are based on the semantic rules of the language.
5) Code Optimization
Since the compiler translates the source program into intermediate code in a mechanical, fixed-pattern manner, the generated intermediate code often has significant time and space waste. When generating efficient target code, optimization must be performed. The optimization process can take place during the intermediate code generation phase or the target code generation phase. Since intermediate code is machine-independent, the optimizations made at this time are generally based on control flow and data flow analysis of the program and are independent of specific machines. The principle on which optimization is based is the equivalence transformation rules of the program.
6) Target Code Generation
Target code generation is the final stage of the compiler’s work. The task of this stage is to transform intermediate code into absolute instruction code, relocatable instruction code, or assembly instruction code for a specific machine; this stage of work is closely related to the specific machine.
7) Symbol Table Management
The symbol table serves to record the necessary information of each symbol in the source program to assist in checking the correctness of semantics and code generation. During the compilation process, fast and efficient operations such as searching, inserting, modifying, and deleting in the symbol table are required. The symbol table can be established starting from the lexical analysis phase or placed in the syntax analysis and semantic analysis phases, but the use of the symbol table may sometimes extend to the runtime phase of the target code.
8) Error Handling
It is inevitable that user-written source programs will contain some errors, which can be roughly divided into static errors and dynamic errors. Dynamic errors, also known as dynamic semantic errors, occur during program execution, such as dividing by zero or referencing an incorrect array element index. Static errors refer to program errors discovered during the compilation phase, which can be divided into syntax errors and static semantic errors, such as spelling errors, punctuation errors, missing operands in expressions, unmatched parentheses, etc. Syntax errors refer to errors related to the structure of the language, while semantic errors discovered during semantic analysis, such as illegal types for operators and operands, fall under static semantic errors.
When errors in the program are discovered during compilation, the compiler should adopt appropriate strategies to correct them, allowing the analysis process to continue, so that as many errors as possible can be identified in a single compilation.
Logically, the various stages of the compilation process can be divided into two parts: the front end and the back end. The front end includes the work from lexical analysis to intermediate code generation, while the back end includes intermediate code optimization and target code generation and optimization. Thus, using intermediate code as a dividing line, the compiler is divided into machine-dependent and machine-independent parts. As a result, after developing a front end for a specific programming language, the corresponding back end can be developed for different machines, and the organic combination of the front and back ends forms a compiler for that language. When the language changes, it will only involve maintaining the front end.
For different programming languages, corresponding front ends can be designed, and then the front ends of each language can be combined with the same back end to obtain compilers for each language on a specific machine.
2. Formal Description of Grammar and Language
A language L is a set of finite-length strings over a finite alphabet ∑, where each string in this set is generated according to certain rules. From the perspective of generating languages, the definitions of grammar and language are given. The so-called generating language refers to establishing a finite number of rules that can generate all sentences of this language.
Noam Chomsky classified grammars into four types: Type 0 (phrase grammar), Type 1 (context-sensitive grammar), Type 2 (context-free grammar), and Type 3 (regular grammar).
3. Lexical Analysis
The smallest syntactic unit with independent meaning in a language is a symbol (word), such as identifiers, unsigned constants, and delimiters. The task of lexical analysis is to convert the strings that make up the source program into a sequence of word symbols. Lexical rules can be described using Type 3 grammar (regular grammar) or regular expressions, and the set it generates is a subset of the basic character set of the language (alphabet), called a regular set.
A finite automaton is an abstract concept of a recognition device that can accurately recognize regular sets. Finite automata are divided into two categories: deterministic finite automata and nondeterministic finite automata.
1) Deterministic Finite Automata (DFA)
A deterministic finite automaton is a five-tuple (S, ∑, f, $s_0$, Z), where:
-
S is a finite set, each of whose elements is called a state.
-
∑ is a finite alphabet, each of whose elements is called an input character.
-
f is a single-valued partial mapping on S * ∑ → S. f(A, a) = Q indicates that when the current state is A and the input is a, it transitions to the next state Q, which is called Q a successor state of A.
-
$s_0 ext{ is the unique start state.}$
-
Z is a non-empty set of accepting states, where $Z ext{ is a subset of } S$.
A DFA can be represented in two intuitive ways: state transition diagrams and state transition matrices. The state transition diagram, referred to as the transition graph, is a directed graph. Each state in the DFA corresponds to a node in the transition graph, and each transition function in the DFA corresponds to a directed arc in the graph. If the transition function is f(A, a) = Q, then the directed arc starts from node A and enters node Q, with character a as the label on the arc.
2) Nondeterministic Finite Automata (NFA)
An NFA is also a five-tuple, and its differences from a DFA are as follows:
-
f is a single-valued partial mapping on $S * ext{Σ} → 2^S$. For a given state in S and input symbol, it returns a set of states. That is, the successor state of the current state is not necessarily unique.
-
The label on the directed arc can be ε.
5. Construction of Lexical Analyzers
With the theoretical foundation of regular expressions and finite automata, the lexical analysis module of the compiler can be constructed. The general steps for constructing a lexical analyzer are as follows.
(1) Use regular expressions to describe the rules for constructing words in the language. (2) For each regular expression, construct an NFA that recognizes the regular set represented by the regular expression. (3) Convert the constructed NFA into an equivalent DFA. (4) Minimize the DFA to make it simplest. (5) Construct the lexical analyzer from the DFA.
6. Syntax Analysis
The task of syntax analysis is to analyze whether the sequence of words constitutes phrases and sentences, i.e., basic language structures such as expressions, statements, and programs, based on the syntactic rules of the language while checking and handling syntax errors in the program. Most of the syntax rules of programming languages can be described using context-free grammar. There are various methods for syntax analysis, which can be divided into bottom-up and top-down categories based on the direction of generating syntax trees.
7. Syntax-Directed Translation and Intermediate Code Generation
The semantics of programming languages can be divided into static semantics and dynamic semantics. The formal methods for describing program semantics mainly include attribute grammars, axiomatic semantics, operational semantics, and referential semantics, among which attribute grammar is an extension of context-free grammar. Currently, the most widely used method for static semantic analysis is syntax-directed translation, which is based on the idea of assigning semantics of language structures in the form of attributes to the grammar symbols representing these structures, while the computation of attributes is given in the form of semantic rules assigned to the productions of the grammar. During the derivation or reduction steps of syntax analysis, the execution of semantic rules achieves the computation of attributes, thus processing the semantics.
1) Intermediate Code
In principle, after performing semantic analysis on the source program, target code can be directly generated. However, due to the often significant structural differences between source programs and target codes, especially considering the characteristics of specific machine instruction systems, it is difficult to achieve one-pass translation. Moreover, the target code mechanically generated using syntax-directed methods is often cumbersome and inefficient. Therefore, it is necessary to design an intermediate code that first translates the source program into an intermediate code representation for machine-independent optimization processing. Since intermediate code also serves as a dividing line between the front end and back end of the compiler, using intermediate code also helps improve the portability of the compiler. Common forms of intermediate code include postfix notation and trees.
(1) Postfix Notation (Reverse Polish Notation). Reverse Polish Notation is a method of representing expressions invented by Polish logician Lukasiewicz. This representation places the operator after the operands, for example, <span>a </span><span>+</span><span> b</span> is written as <span>a b </span><span>+</span>, hence it is also called postfix notation. The advantage of this representation is that it allows calculations based on the order of appearance of operands and operators without needing parentheses and is easy to evaluate using a stack. For the expression <span>x </span><span>:=</span><span> </span><span>(</span><span>a </span><span>+</span><span> b</span><span>)</span><span> </span><span>*</span><span> </span><span>(</span><span>c </span><span>+</span><span> d</span><span>)</span>, its postfix notation would be <span>x a b </span><span>+</span><span> c d </span><span>+</span><span> </span><span>*</span><span> </span><span>:=</span>.
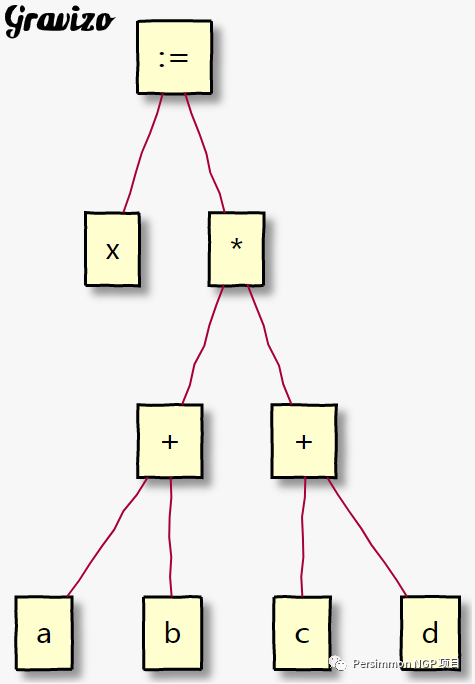
(2) Tree Representation. For example, the expression <span>x </span><span>:=</span><span> </span><span>(</span><span>a </span><span>+</span><span> b</span><span>)</span><span> </span><span>*</span><span> </span><span>(</span><span>c </span><span>+</span><span> d</span><span>)</span> has the tree representation:
8. Intermediate Code Optimization and Target Code Generation
Optimization refers to performing equivalent transformations on programs to generate more efficient target code from the transformed program. The term equivalent means that the program’s execution result does not change; effective means that the running time of the target code is shorter and occupies less storage space. Optimization can be performed at various stages of compilation. The most significant optimization occurs before generating target code from intermediate code, and this optimization does not depend on specific computers.
The generation of target code is implemented by the code generator. The code generator takes intermediate code that has undergone semantic analysis or optimization as input and produces specific machine language or assembly code as output. The main issues to consider during code generation are described below.
(1) Form of Intermediate Code. There are many forms of intermediate code, among which tree and postfix representations are suitable for interpreters, while compilers often use four-address code that is closer to machine instruction formats.
(2) Form of Target Code. Target code can be divided into two main categories: assembly language form and machine instruction form. The machine instruction form of target code can be further divided into absolute machine instruction code and relocatable machine code based on different needs. The advantage of absolute machine code is that it can be executed immediately, commonly used in a compilation mode called load-and-go, where the code is executed immediately after compilation without forming a target code file stored on external memory. The advantage of relocatable machine code is that it can be linked and loaded into any position in memory, making it a common code form used by compilers. Assembly language, as an intermediate output form, is convenient for analysis and testing.
(3) Register Allocation. Since accessing registers is much faster than accessing memory units, there is a constant desire to store as much data as possible in registers, but the number of registers is limited. Therefore, how to allocate and use registers is a key consideration during target code generation.
(4) Choice of Calculation Order. The efficiency of code execution can vary significantly depending on the order of calculations. Arranging the order of calculations appropriately while generating correct target code and optimizing the code sequence is also an important factor to consider during target code generation.
2.2.3 Basic Principles of Interpreters
An interpreter is another type of language processor that works similarly to a compiler in terms of lexical, syntax, and semantic analysis. However, when running user programs, it directly executes the source program or the intermediate representation of the source program. Therefore, interpreters do not produce target programs from source programs, which is the main difference between them and compilers.
Interpreters can directly execute the source program, checking it character by character and then executing the actions specified by the program statements. This type of interpreter achieves program execution by repeatedly scanning the source program, resulting in low execution efficiency.
Interpreters can also first translate the source program into a certain intermediate code form and then interpret this intermediate code to execute the user program. Typically, there is a one-to-one correspondence between intermediate code and high-level language statements; many implementations of APL and SNOBOL4 adopt this method. The intermediate code used by interpreters can also be closer to machine language, with a one-to-many correspondence between high-level languages and low-level intermediate codes. The PASCAL-P interpreter system is an example of this type of interpreter, which first translates programs into P-code after lexical analysis, syntax analysis, and semantic analysis, and then a very simple interpreter interprets and executes this P-code. Such systems have relatively good portability.
1. Basic Structure of Interpreters
Interpreters can usually be divided into two parts: the first part is the analysis part, which includes the usual lexical analysis, syntax analysis, and semantic analysis programs. After semantic analysis, the source program is translated into intermediate code, which is often in reverse Polish notation. The second part is the interpretation part, which is used to interpret and execute the intermediate code generated by the first part.
2. Comparison of Compilation and Interpretation of High-Level Languages
The compilation and interpretation of high-level languages can be compared from the following aspects.
1) Efficiency
Compilation can achieve higher efficiency than interpretation.
Generally speaking, when a program runs under interpretation, the interpreter may need to repeatedly scan the source program. For example, each time a variable is referenced, type checking may be required, and even storage allocation may need to be redone, thus reducing the program’s execution speed. In terms of space, running a program under interpretation requires more memory because the system needs to allocate runtime space for both the user program and the interpreter and its supporting system.
In the compilation approach, the compiler not only performs syntax and semantic analysis on the source program but also generates the target code and performs optimization. Thus, this process takes more time than the interpretation method. Although the target program created by the compiler generally takes longer to run and occupies more storage space than a carefully written machine program, the source program only needs to be translated once by the compiler to run multiple times. Therefore, overall, the compilation method can achieve higher efficiency than interpretation.
2) Flexibility
Due to the need for the interpreter to repeatedly check the source program, this also allows the interpretation method to be more flexible than the compilation method. When the interpreter runs the source program directly, modifications to the program “on the fly” become possible, such as adding statements or correcting errors. Additionally, when the interpreter works directly on the source program, it can pinpoint errors more accurately.
3) Portability
Interpreters are generally written in some programming language, so as long as the interpreter is recompiled, it can run in different environments.
Since both compilation and interpretation methods have their characteristics, some existing compilation systems provide both compilation and interpretation methods, and even combine the two methods. For example, a new technology called just-in-time compilation developed on the Java Virtual Machine compiles the code the first time it runs, and no further compilation is done during subsequent runs.