 At the top conference in the field of architecture, MICRO (IEEE/ACM International Symposium on Microarchitecture, CCF-A class) in 2024, four papers from the National Key Laboratory of Processor Chips at the Institute of Computing Technology, Chinese Academy of Sciences (hereinafter referred to as the “Laboratory”) were accepted: “Cambricon-LLM: A Chiplet-Based Hybrid Architecture for On-Device Inference of 70B LLM”, “Cambricon-M: a Fibonacci-coded Charge-domain SRAM-based CIM Accelerator for DNN Inference”, “Cambricon-C: Efficient 4-bit Matrix Unit via Primitivization”, and “TMiner: A Vertex-Based Task Scheduling Architecture for Graph Pattern Mining”.
At the top conference in the field of architecture, MICRO (IEEE/ACM International Symposium on Microarchitecture, CCF-A class) in 2024, four papers from the National Key Laboratory of Processor Chips at the Institute of Computing Technology, Chinese Academy of Sciences (hereinafter referred to as the “Laboratory”) were accepted: “Cambricon-LLM: A Chiplet-Based Hybrid Architecture for On-Device Inference of 70B LLM”, “Cambricon-M: a Fibonacci-coded Charge-domain SRAM-based CIM Accelerator for DNN Inference”, “Cambricon-C: Efficient 4-bit Matrix Unit via Primitivization”, and “TMiner: A Vertex-Based Task Scheduling Architecture for Graph Pattern Mining”.
The first author of the paper “Cambricon-LLM: A Chiplet-Based Hybrid Architecture for On-Device Inference of 70B LLM” is master’s student Yu Zhongkai from the Laboratory. Cambricon-LLM is the first acceleration architecture that supports the deployment of a 70B scale large language model on edge devices. Deploying advanced large language models on edge devices such as smartphones and robots enhances user data privacy and reduces reliance on network connectivity. However, this task exhibits characteristics of small computation batches (usually 1) and low computational intensity, posing dual challenges of memory usage and bandwidth demand on limited edge resources. To address these issues, Cambricon-LLM designs a hybrid architecture based on chiplet technology, integrating NPU and dedicated NAND flash memory chips. First, Cambricon-LLM utilizes the high storage density of NAND flash memory chips to store model weights and adds in-die computation and in-die error correction capabilities to alleviate bandwidth pressure while maintaining model inference accuracy. Second, Cambricon-LLM combines hardware-aware slicing technology, allowing the NPU and flash memory chips to collaborate on matrix operations, achieving reasonable utilization of hardware resources. Overall, Cambricon-LLM is 22 to 45 times faster than existing flash offloading technologies, demonstrating the potential for deploying powerful LLMs on edge devices.
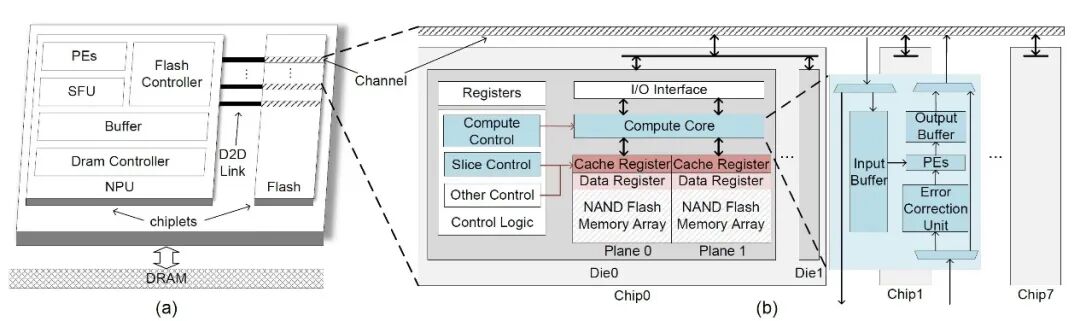
Figure 1. Cambricon-LLM Architecture Diagram
The first author of the paper “Cambricon-M: a Fibonacci-coded Charge-domain SRAM-based CIM Accelerator for DNN Inference” is doctoral student Guo Hongrui from the Laboratory. Cambricon-M is a charge-domain SRAM-based compute-in-memory architecture based on Fibonacci coding. The compute-in-memory structure reduces data movement between computing units and memory, showing broad application prospects, with charge-domain SRAM compute-in-memory architecture becoming a research hotspot in recent years. Research has found that the input voltage of the analog-to-digital converter (ADC) (i.e., the output voltage of the SRAM array) has a large dynamic range, requiring high-resolution ADCs to convert high-precision analog voltages into high-bit-width digital domain data to avoid precision loss. However, high-resolution ADCs have gradually become an energy bottleneck (accounting for up to 64%), limiting the development of charge-domain SRAM compute-in-memory architecture. Cambricon-M employs Fibonacci coding to ensure that every ‘1’ in the input has adjacent ‘0’s, reducing the density of ‘1’s in the operands, thereby narrowing the range of the SRAM array output voltage (i.e., the input voltage of the ADC), allowing the use of low-resolution ADCs in charge-domain SRAM compute-in-memory architecture, reducing energy consumption and minimizing precision loss. Additionally, Cambricon-M utilizes various techniques such as bit-level sparsity to address the extra energy and area overhead introduced by high-bit-width Fibonacci coding. Experimental results show that Cambricon-M reduces ADC energy consumption by 68.7%, achieving 3.48 times and 1.62 times energy efficiency improvements compared to existing digital domain and charge domain accelerators, respectively.
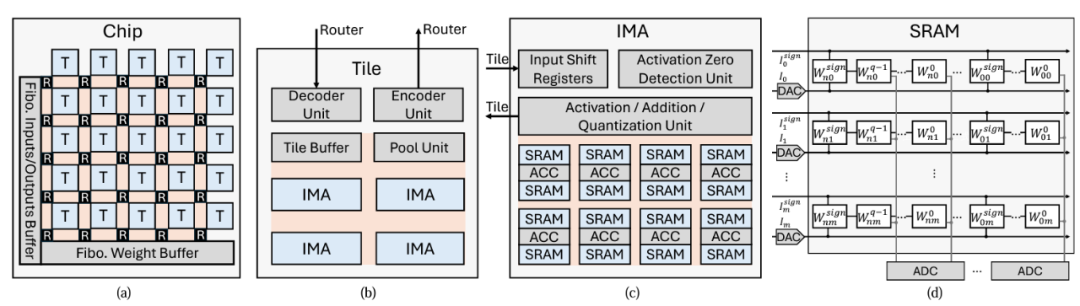
Figure 2. Cambricon-M Architecture Diagram
The first author of the paper “Cambricon-C: Efficient 4-bit Matrix Unit via Primitivization” is master’s student Chen Yi from the Laboratory. Cambricon-C is an accelerator design for low-precision matrix multiplication. Deep learning often uses low-precision data formats to cope with the growing model scale, reducing the hardware overhead of model deployment. However, as data precision decreases, the power efficiency of multiply-accumulate matrix multiplication units gradually slows down, severely limited by repetitive low-precision numerical multiplication and high-bit-width numerical addition. To address this issue, Cambricon-C initializes the matrix multiplication algorithm, reducing the multiply-accumulate operation to a unary operation—accumulation, optimizing the original matrix multiplication algorithm with quarter multiplications to avoid repetitive multiplication operations, reducing the intensity of addition hardware, and achieving practical gains. The pulsed array of Cambricon-C saves about 1.95x power compared to pulsed arrays based on multiply-accumulate units, and the complete Cambricon-C accelerator achieves 1.13 – 1.25x power savings compared to traditional TPU accelerators when processing quantized neural networks.
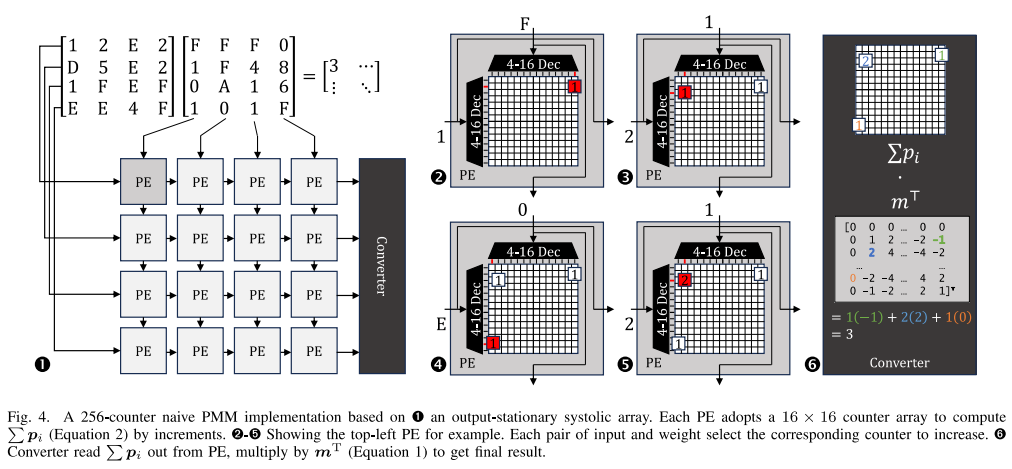
Figure 3. Cambricon-C Schematic Diagram, Using 256 Counters to Implement the Initialized Matrix Multiplication Hardware Based on: 1. Output stationary pulsed array; 2-5. Each pair of activations and weights triggers the corresponding counter for accumulation; 6. The final result is calculated using the recorded values of the counters and a pre-computed lookup table.
The first author of the paper “TMiner: A Vertex-Based Task Scheduling Architecture for Graph Pattern Mining” is doctoral student Li Zerun from the Laboratory. TMiner is an accelerator for graph pattern mining based on near-memory computing technology. Graph pattern mining is used to search for subgraphs isomorphic to a given pattern and is widely applied in bioinformatics, network security, social network analysis, and other fields. Existing graph pattern mining systems suffer from multiple levels of redundant memory access: 1. Multiple computing units simultaneously access the same data, causing redundant DRAM or Last Level Cache accesses and reducing the effective capacity of the Cache; 2. The same computing unit repeatedly accesses the same data at discrete times, causing redundant DRAM accesses; 3. A computing task splits access to a complete set into accesses to multiple subsets, causing both redundant DRAM accesses and breaking the continuity of memory access. TMiner partitions tasks based on memory access behavior during the design phase, ensuring that memory accesses of different computing units do not overlap, eliminating redundant memory accesses between computing units; during the compilation phase, it merges accesses to multiple subsets into accesses to a superset, eliminating redundant memory accesses within tasks; at runtime, it merges tasks with the same data requirements for execution, eliminating redundant memory accesses within computing units. Through these optimizations, TMiner eliminates a large amount of redundant memory access without sacrificing parallelism, achieving an average performance improvement of 3.5 times across datasets and various patterns in social networks, communication networks, etc.
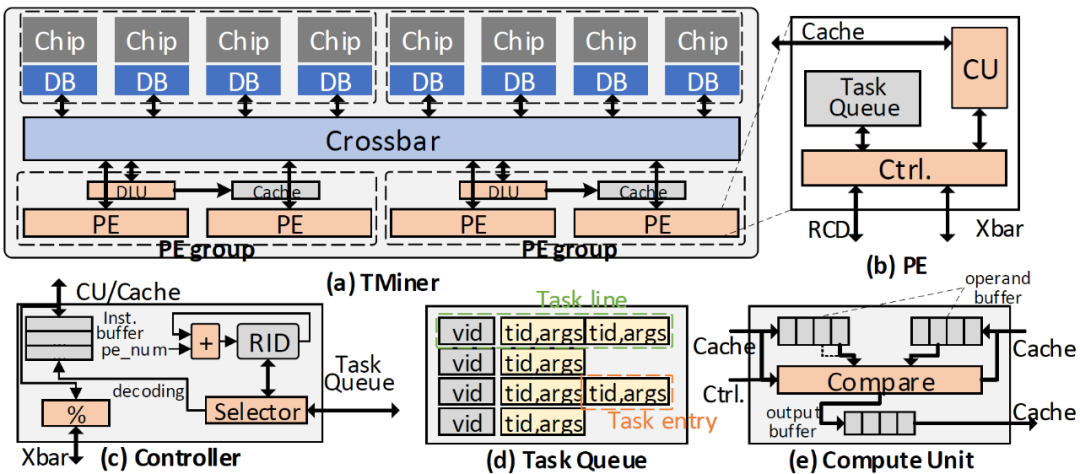
Figure 4. TMiner Hardware Architecture. (a) Overall architecture, (b) PE architecture, (c) controller design, (d) task queue design, (e) computing unit design.
In addition, the paper “SRender: Boosting Neural Radiance Field Efficiency via Sensitivity-Aware Dynamic Precision Rendering”, co-authored by the Laboratory and Shanghai Jiao Tong University, was also accepted at MICRO. SRender is the first to transfer the adaptive rendering technology used in traditional image rendering to neural rendering, proposing a variable precision quantization scheme based on data sensitivity, and addressing the block conflict issue with a coarse-fine granularity combined data rearrangement mechanism, achieving real-time rendering effects at 56 FPS.
The MICRO conference mainly collects research advances in the fields of microarchitecture, compilers, chips, and systems. Since its first meeting in 1968, MICRO has become a top conference in the field of computer architecture and is one of the most important academic conferences in the global computer architecture field, playing a crucial role in promoting research and development in this area. This year’s conference received 497 submissions, with 113 accepted, resulting in an acceptance rate of 22.7%.
