VxWorks is widely used in fields requiring high reliability and real-time performance, such as communication, military, aviation, and aerospace, including satellite communication, military exercises, ballistic guidance, and aircraft navigation.
American F-16, F/A-18 fighters, B-2 stealth bombers, and Patriot missiles, as well as Mars rovers like the Mars Pathfinder that landed in July 1997, the Phoenix lander in May 2008, and the Curiosity rover in August 2012, all utilize VxWorks.
After encountering VxWorks firmware multiple times, I have gained new insights each time. From being at a loss to having a slight understanding of what to do. Missing symbol tables can actually be inferred based on string hints and the identification of statically compiled library functions, and sometimes we can carefully find and restore some residual symbol tables.
However, when encountering certain routing functions, it may be impossible to analyze the entire data flow if we cannot see the routed file.
Because, binwalk often presents the VxWorks firmware in a chaotic manner, with very confusing naming, but if you actually open it, the internal content is usually normal.
Upon reflection, when the VxWorks system starts, there must be some references to recover the filenames and locations; otherwise, how could routing be done? This led to the exploration of VxWorks filename recovery and automation.
Finding Offset Tables and File Naming
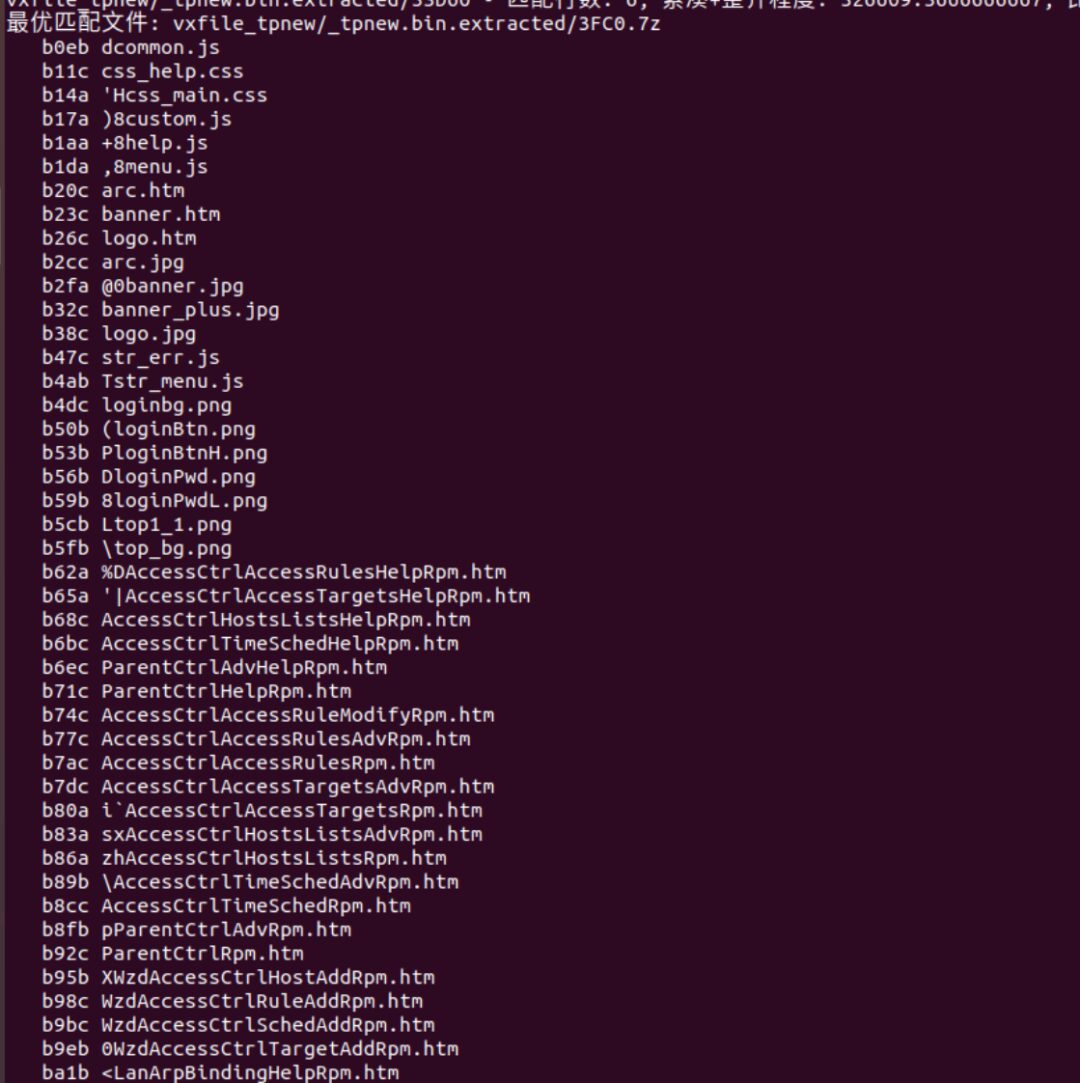
Since we want to recover filenames, we can grep for the filenames to find this table.
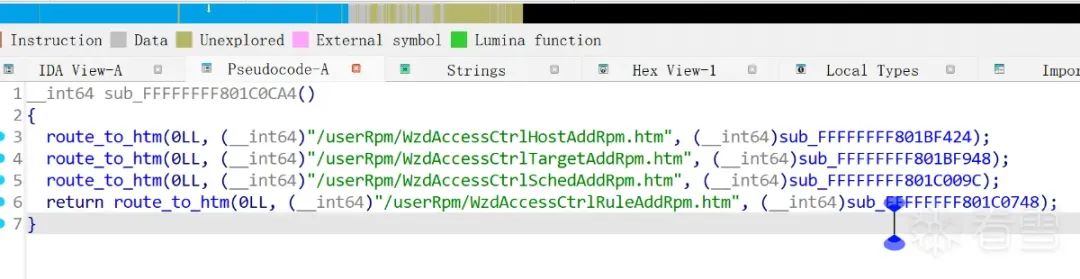
Taking the second example from the above image: /userRpm/WzdAccessCtrlTargetAddRpm.htm, grep -r “WzdAccessCtrlTargetAddRpm.htm” can yield these results:

We can see that two other files (which are also htm files) defined the form and submitted data to WzdAccessCtrlTargetAddRpm.htm.
Unfortunately, we don’t even know the names of these two htm files, which makes it difficult to analyze the data flow.
Returning to the main topic, two files reference this htm, named according to their respective offsets in the firmware (3FC0, 53D60).
In fact, these two files have origins; 3FC0 is actually the uImage image.
To clarify, the 3FC0 file is not a complete uImage; the file named 3FC0.7z by binwalk is actually the complete uImage image file.

Meanwhile, the size of 0x53D60 is significantly larger than other LZMA compressed areas, which is actually the main program bin file of VxWorks, also the key file we usually analyze.

So a reasonable explanation is that 53D60 contains this string because it is routed during web service.
And 3FC0 (uImage), as the boot image of VxWorks, has this string solely for the purpose of recovering filenames and structures. Therefore, if there is an offset table, it should be inside the uImage. Let’s put 3FC0.7z into 010editor and take a look:
First, the initial boot part, which contains program codes:
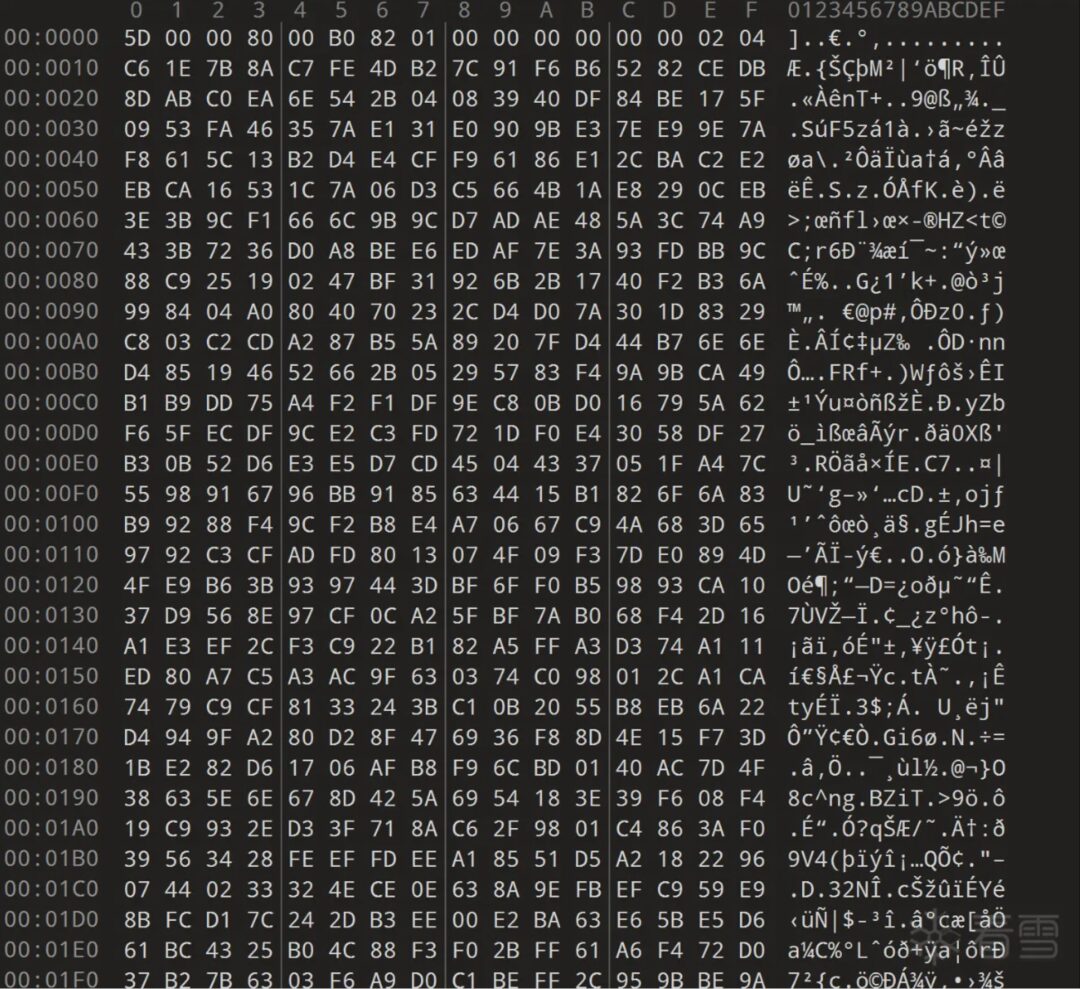
Searching for “.htm” or “.png” strings can lead us to a neat table.
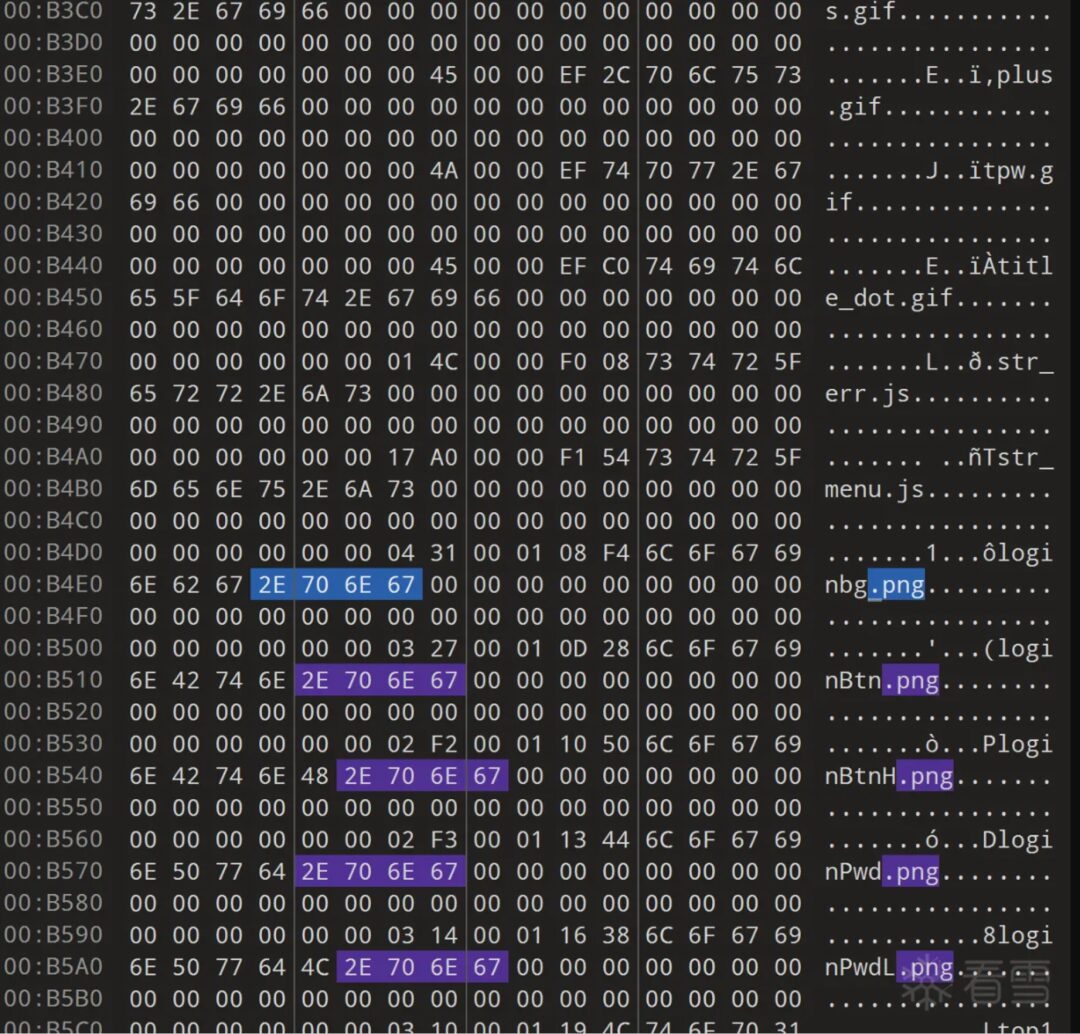
We can see that there seems to be a record of offsets in front of the filenames, but for now, it’s still a guess.
If we can find a correct calculation method, we can completely match the offsets generated by binwalk, which would indicate that this can indeed be used to recover filenames.
Thus, we have found the most critical table item, while specific details still need further exploration.
Confirming the Correspondence Between Filenames and Offsets
Offset Table Structure
A common misconception at the beginning is thinking that the front of the filename corresponds to its size and offset. I calculated a dozen of them and found something wrong: why is there always 1-2 offsets of other file types for each type of file, while the others correspond to the same type?
In fact, after a string of 00 00 00 00 in front of the filename, the size and offset follow:

Determining the Filesystem Offset
Some firmware, like this case, will record the filesystem offset (even if not recorded, there can be very compatible solutions, which will be discussed in the next section).
In fact, the offset in the table + filesystem offset will correspond to the filenames unpacked by binwalk, that is, the offset values in the firmware. This is the method for VxWorks filename recovery.
Hands-On Experiment: Offset Calculation
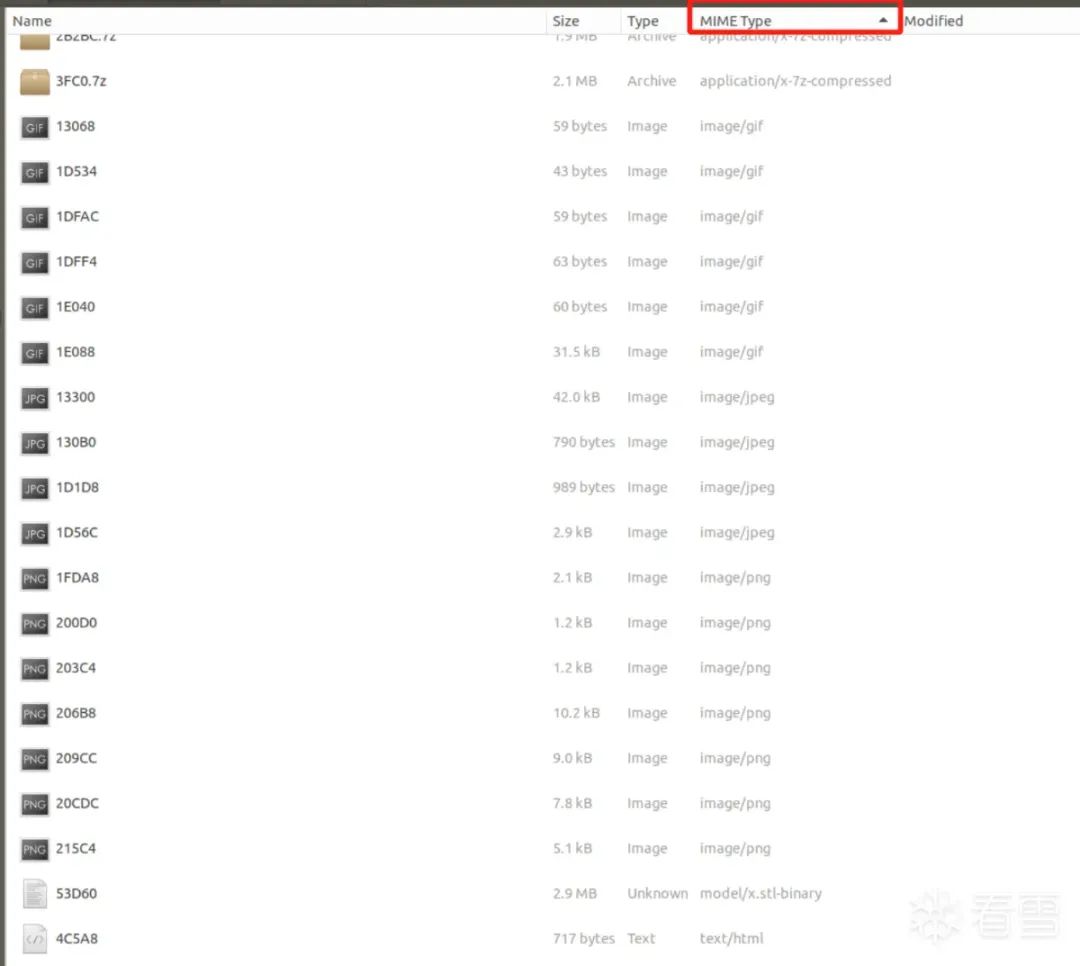
During repeated tests, I found that the VxWorks filesystem often uses a combination of filesystem offset 0xF080 + xxx. For example, using png as a test case: first, sort by MIME type, as the offset table itself is arranged by type, making experimentation easier.
Then, using png as an example, perform offset calculation tests. We can find the following .png characters in tools like 010editor.
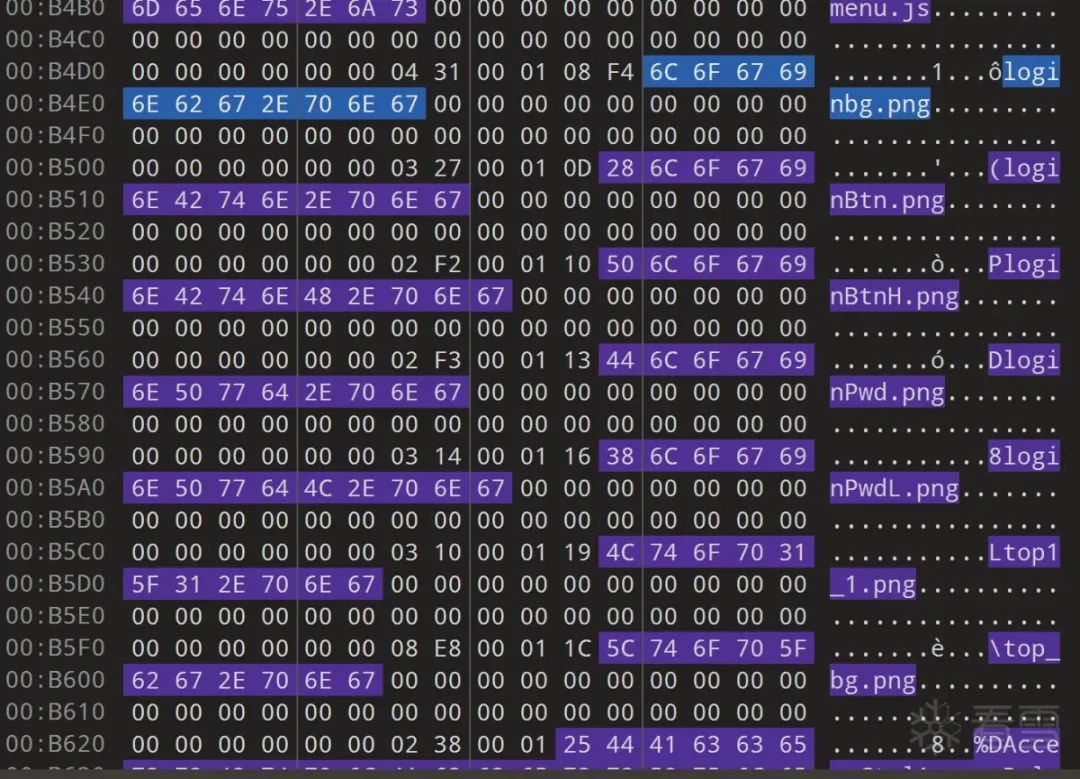
Extract the offsets one by one and add the previously mentioned 0xF080 to get some offsets:
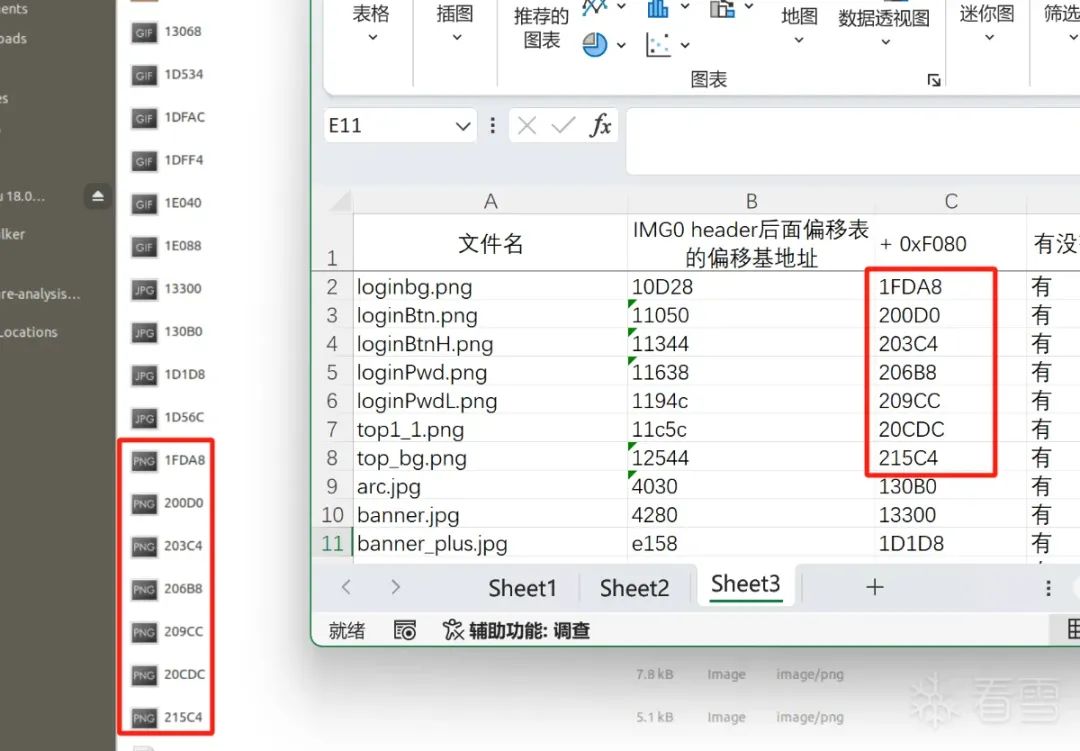
As shown, all filenames can find corresponding offsets, indicating that this method is feasible: for example, we can know that the binwalk parsed 1FDA8 is actually called loginbg.png, etc. (the Excel statement used is =DEC2HEX(HEX2DEC(B2) + HEX2DEC(“F080”)), which helps speed up the testing process without using a calculator each time).
Next, let’s test jpg and gif to find the corresponding table items:
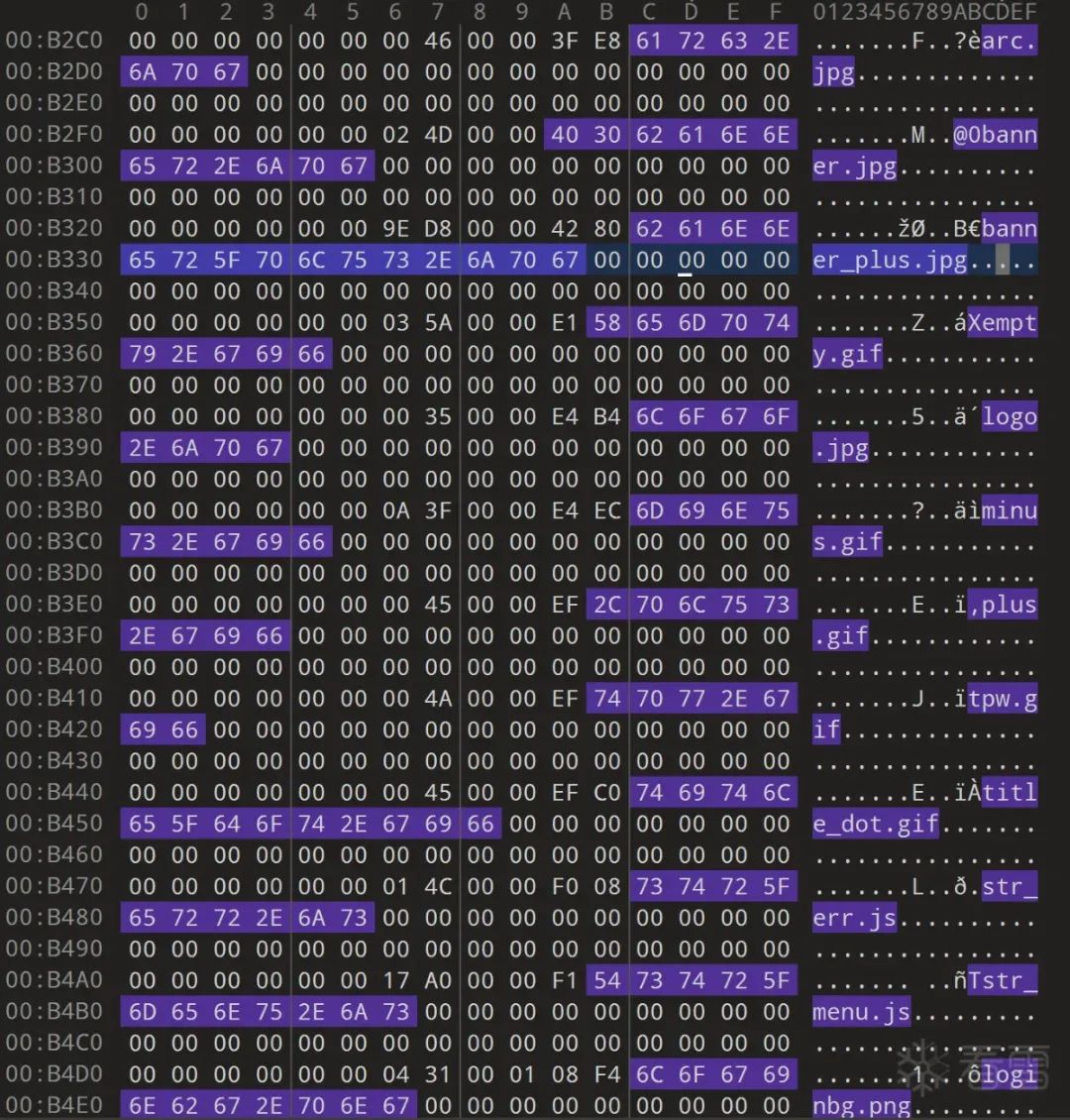
The experimental results are as follows:
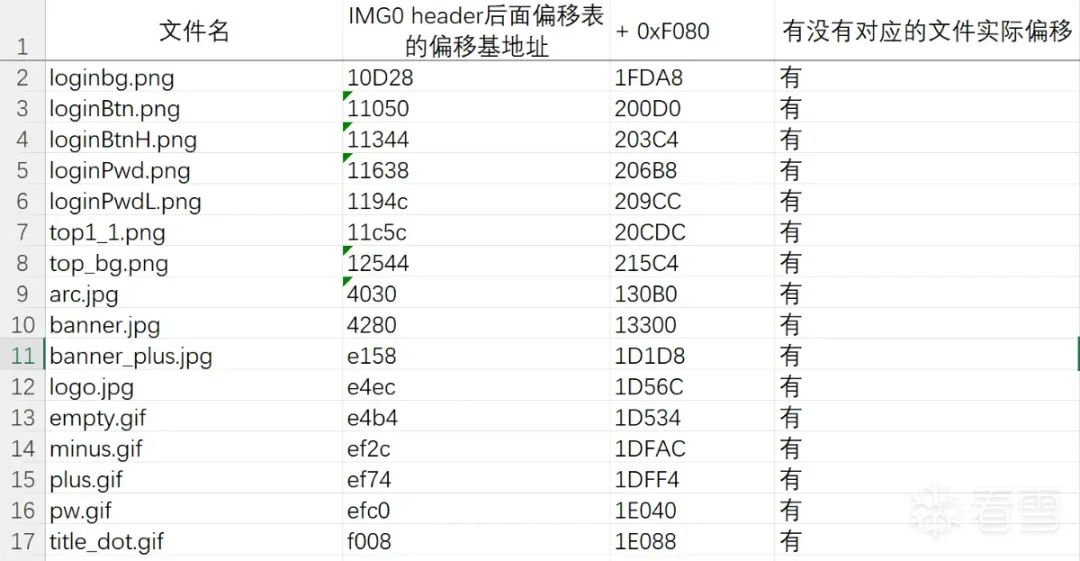
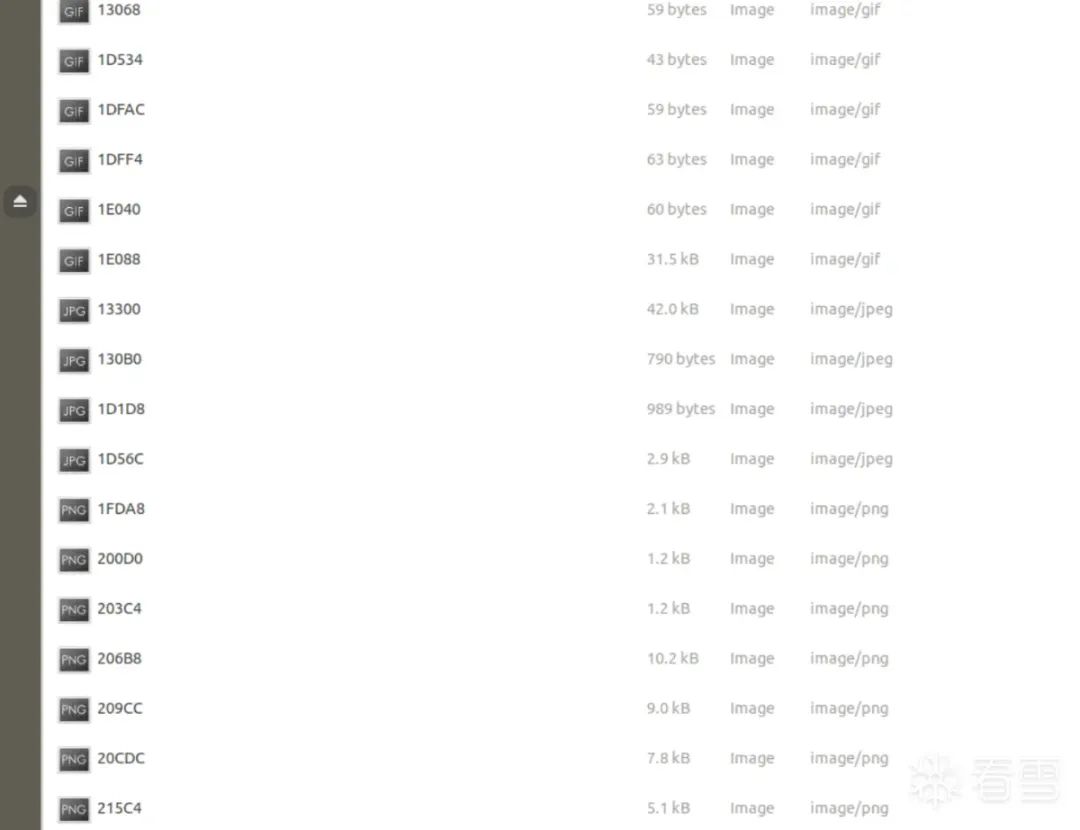
All correct; it seems the method is valid.
Thinking About Automating the VxWorks Filename Recovery Process
Next, I want to automate this complicated process, aiming to extract and recover with one click like binwalk, and for future repeated use, a relatively reliable design is needed.
Next, I will introduce some peculiar design aspects to ensure better compatibility.
Basic Design
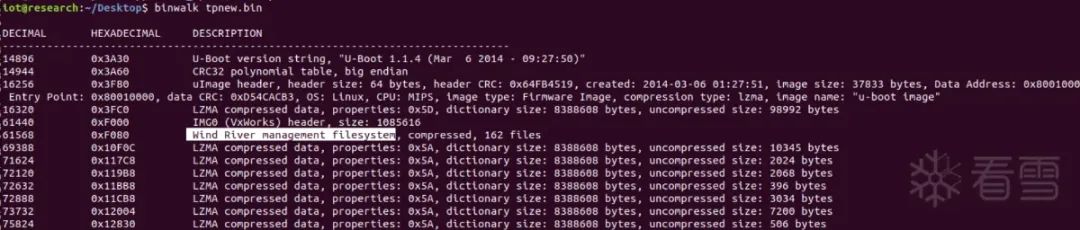
First, binwalk’s various file label recognition is quite impressive, so we must use the results of binwalk. At the same time, we need to run binwalk -Me to extract all files.
It’s best to have a different path from the default to avoid users modifying filenames during previous VxWorks explorations, which could lead to some files being untraceable.
In the binwalk results, the IMG0 (VxWorks) header will be a concentration point of much information, with the uImage offset before it and the filesystem after it, so there will be specific string matching.
How to Automatically Extract the Filesystem Offset
Then, we need to read the filesystem offset address behind the IMG0 (VxWorks) header:
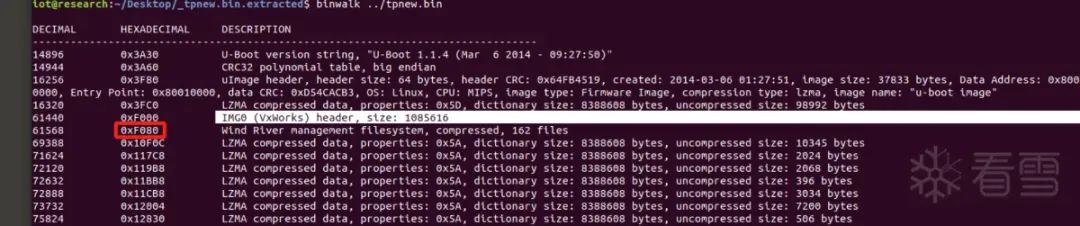
Experiments show that in some cases, the offset is not directly below the IMG0 (VxWorks) header but a few lines below it.
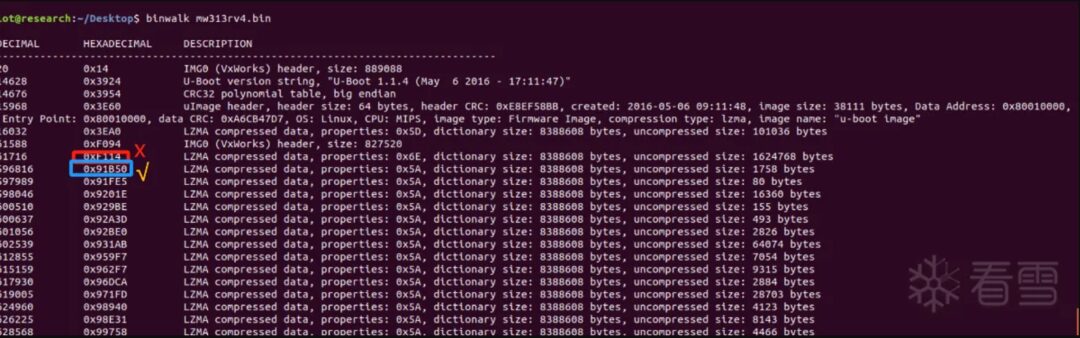
Therefore, to enhance the script’s compatibility, I designed it to try the offsets of the three lines after the IMG0 (VxWorks) header, which should not pose significant compatibility issues.
How to Automatically Extract the Offset Table in the uImage
Next, we need to find the area in front of the IMG0 (VxWorks) header, such as 0x3FC0, where we store the table we need.
How to automatically determine the position of this table so we don’t have to manually open HxD and 010editor to give the program this parameter?
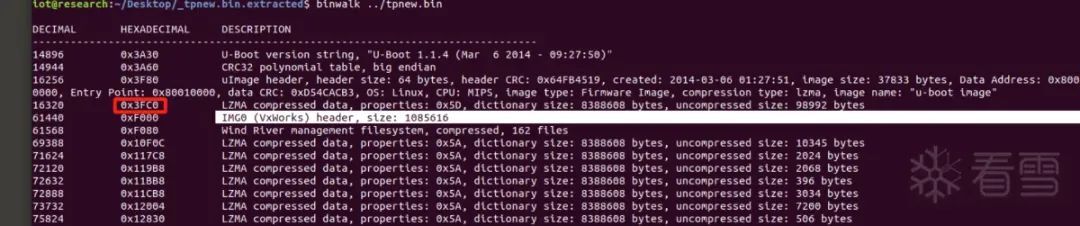
But the problem arises, as previously mentioned, the initial boot part contains only program codes:
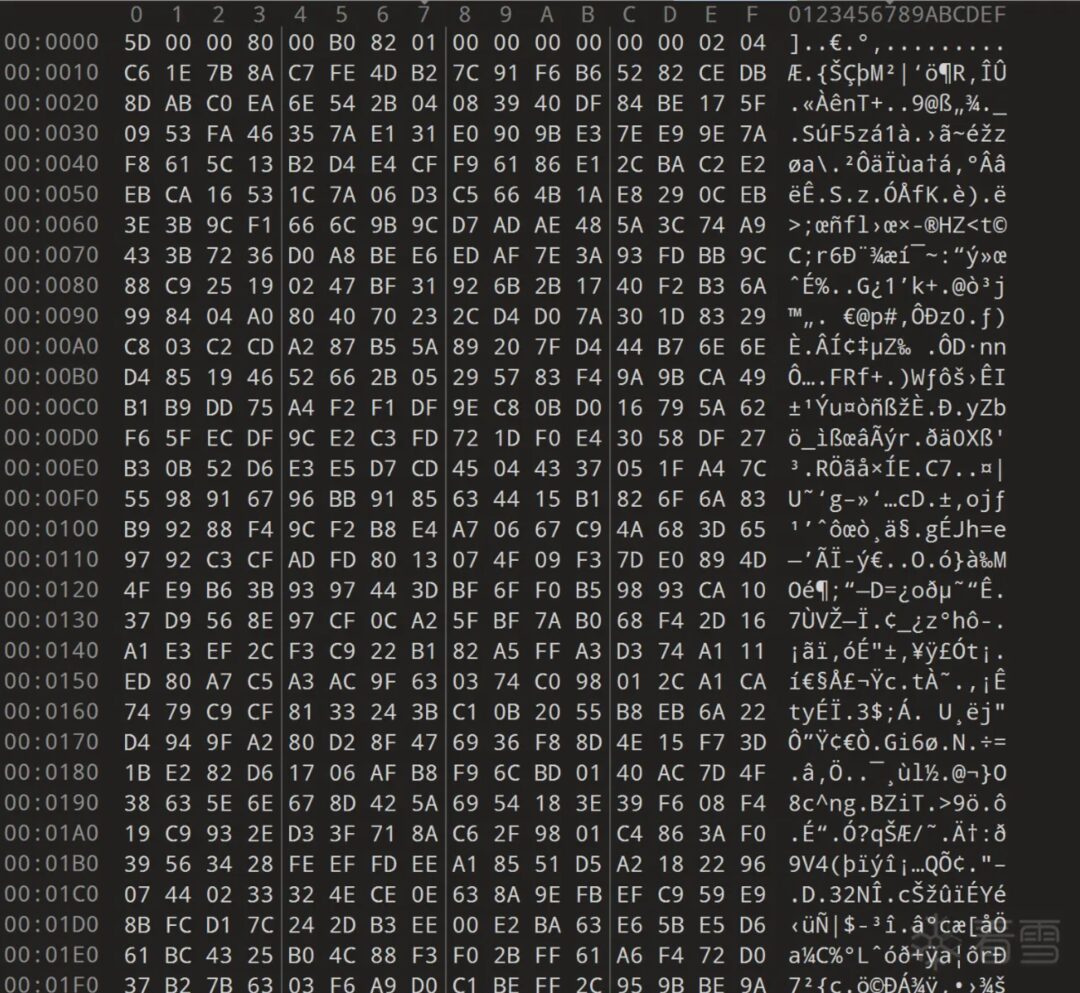
The good news is that after the consecutive boot code, there will be a large area of 00 bytes. The idea is to detect how many consecutive 00s there are, and then switch to searching for the header; if we detect characters again, it is likely to be our IMG0 header (right? Oh, Blakes).

Yes and no; some firmware has multiple segments of boot code, specifically showing as: program segment 1 + “00 00 00 00” * n + program segment 2 + “00 00 00 00” * n + program segment 3 + “00 00 00 00” * n + offset table.
Therefore, simply matching multiple occurrences of the 00 bytes will not work, as this may lead the program to match program segment 2.
For example, in the Mercury series mw313r, the table entry is hidden after three program segments at 0x8b1f0, which made me realize the need for compatibility.
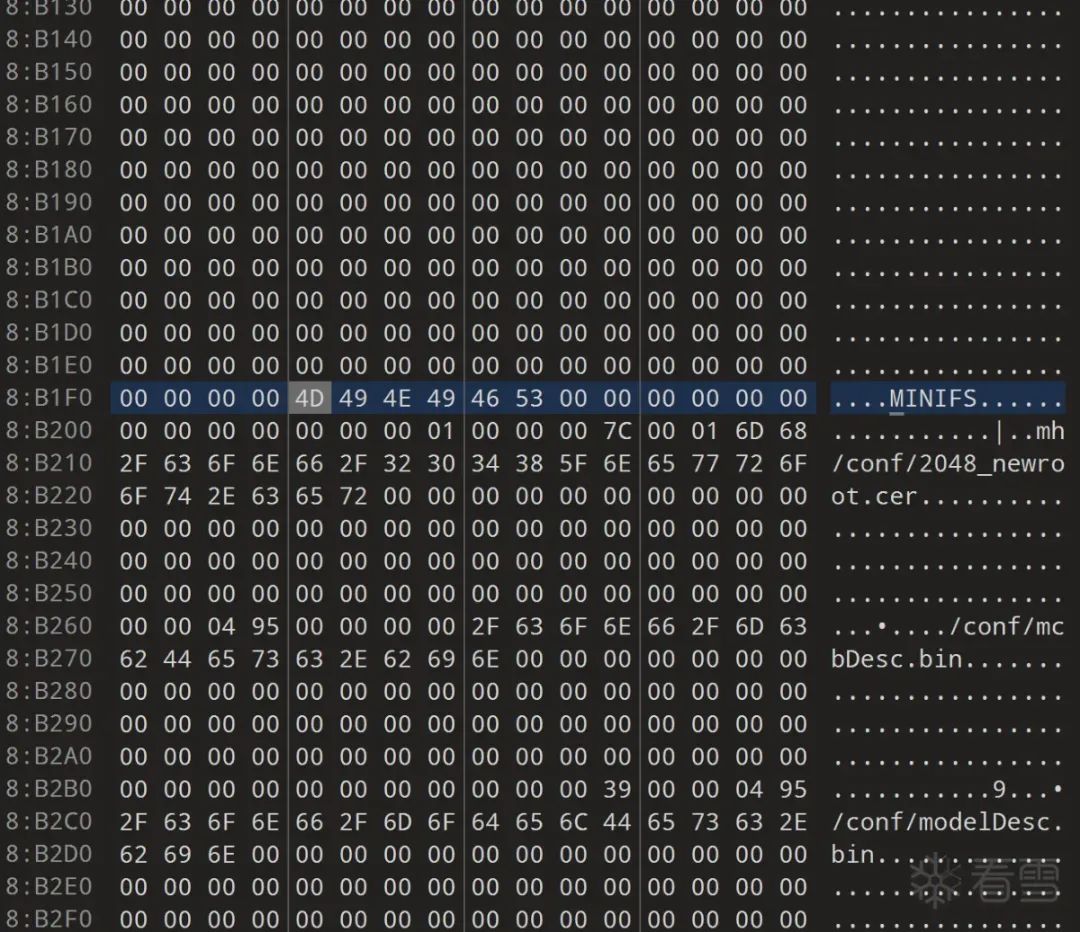
Finally, the solution taken is to detect the validity of the name when using the extract_file_info() function to extract information. If the filename cannot be extracted (if consecutive failures reach a certain threshold, it indicates abnormality), the search for the offset table will restart from the point of filename extraction failure.
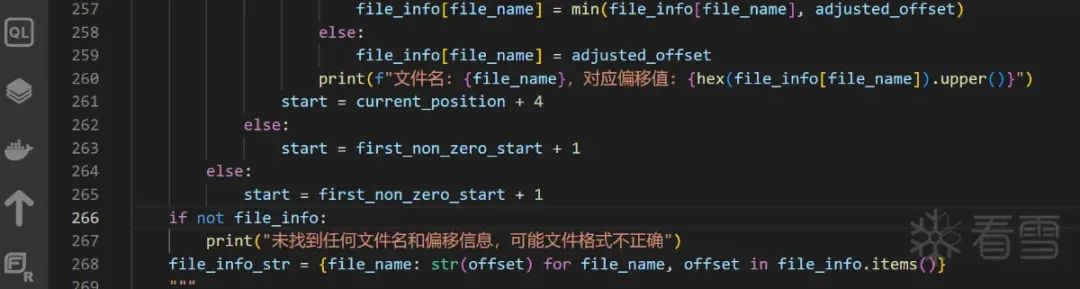
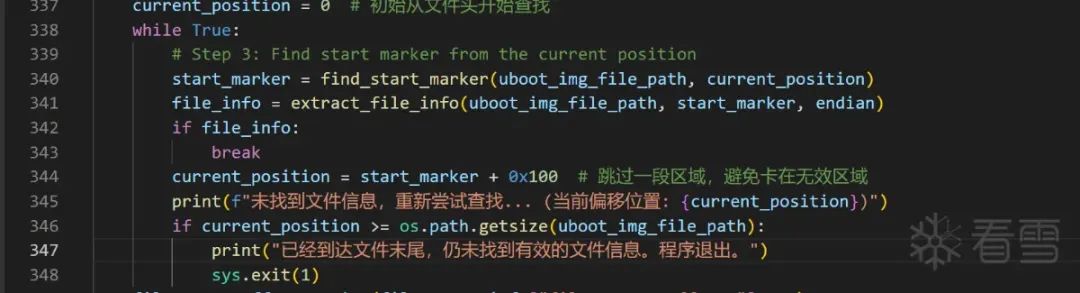
How to Correctly Identify Filenames
Correctly identifying a filename means determining the start of a file offset record block, which can also solve the offset extraction issue.
Only valid characters for these filenames are: uppercase and lowercase letters, numbers, underscores, hyphens, slashes, and there must be a “.” symbol, as all files encountered in VxWorks so far have extensions, even binary files.
Furthermore, filenames will be extracted in a way that aligns with 4-byte boundaries. Overall, this regex matching improves accuracy; for example, the string below owowowow… will not be matched.
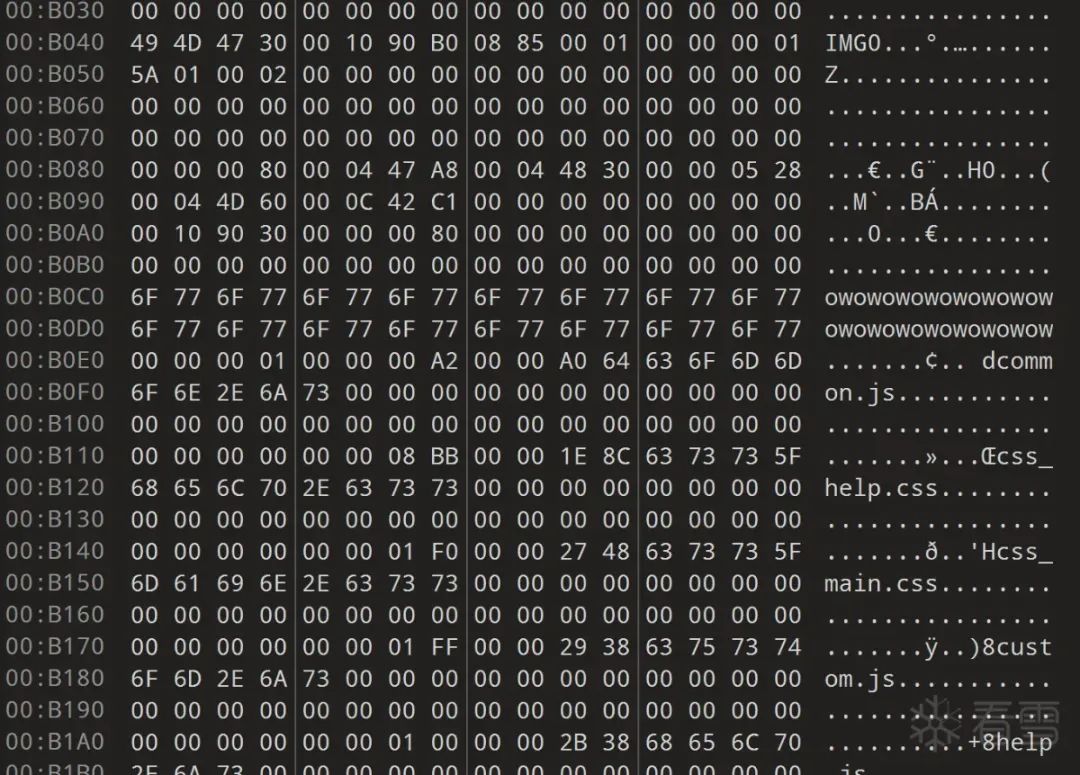
In case some files contain bad strings that meet these rules, there are two last methods: length limitation (besides meeting these rules, the filename length must also be >= 5).
In the end, during the file renaming phase, a filename will only be referenced if it matches a specific file offset; otherwise, it will be discarded.
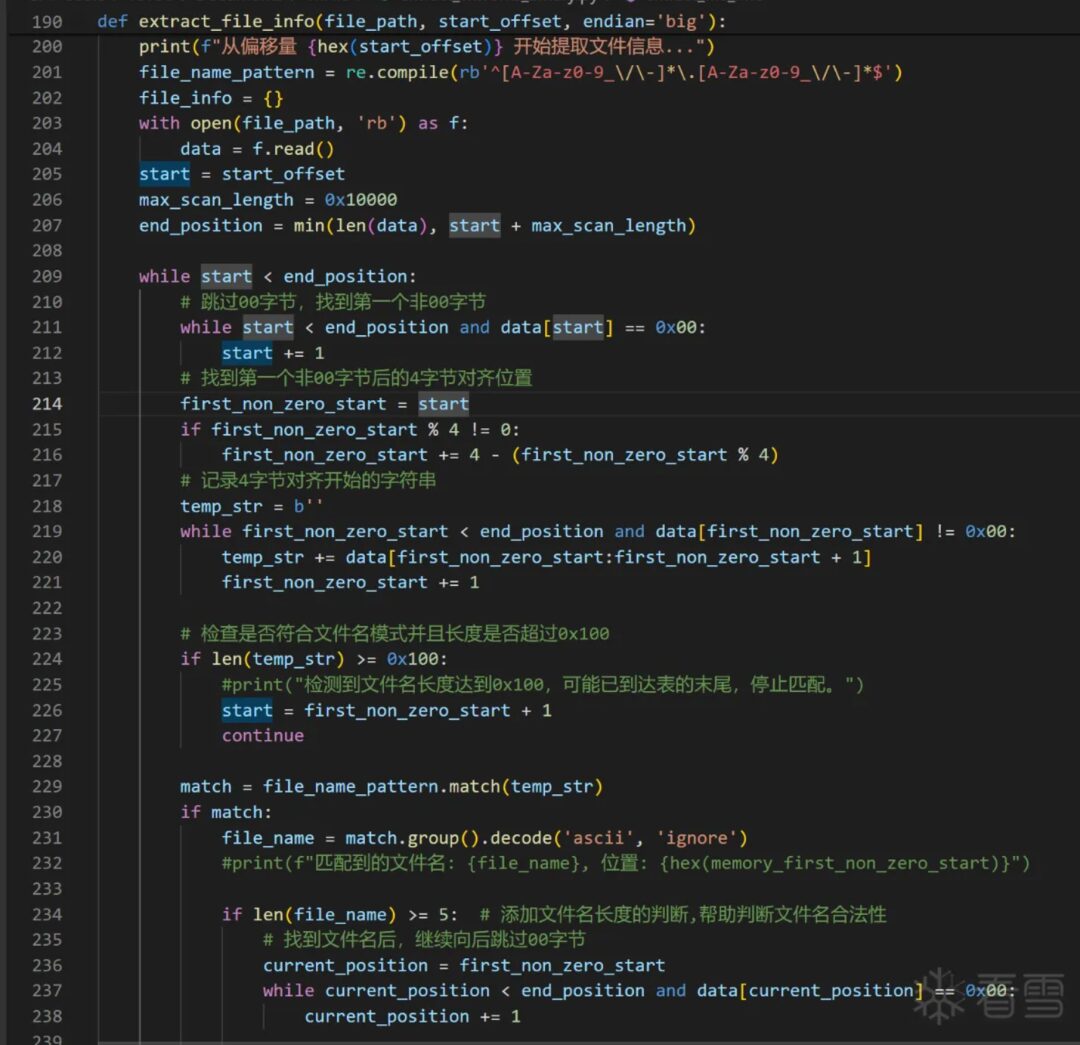
Lastly, how do we know when the filename extraction has reached the end?
Actually, when extracting the next filename, if we detect 100 consecutive non-00 characters, it indicates that extraction has reached the end, as the next part will be the next program segment.
Correctly Recovering Filenames
Correctly recovering filenames also requires considering one thing: some firmware filenames are as follows and do not have paths.
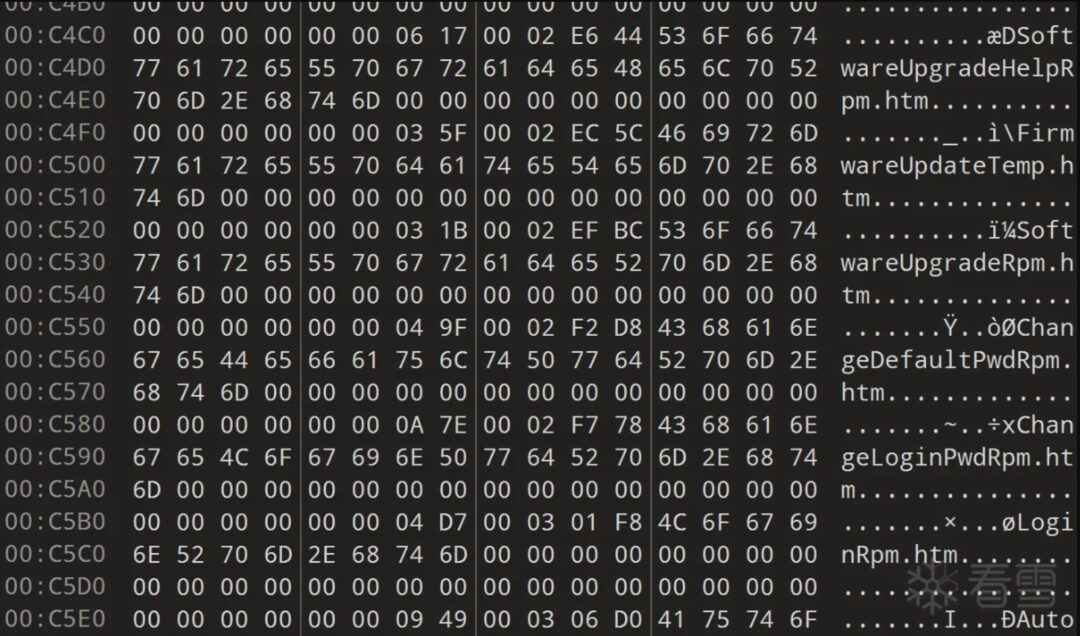
While others do have paths:
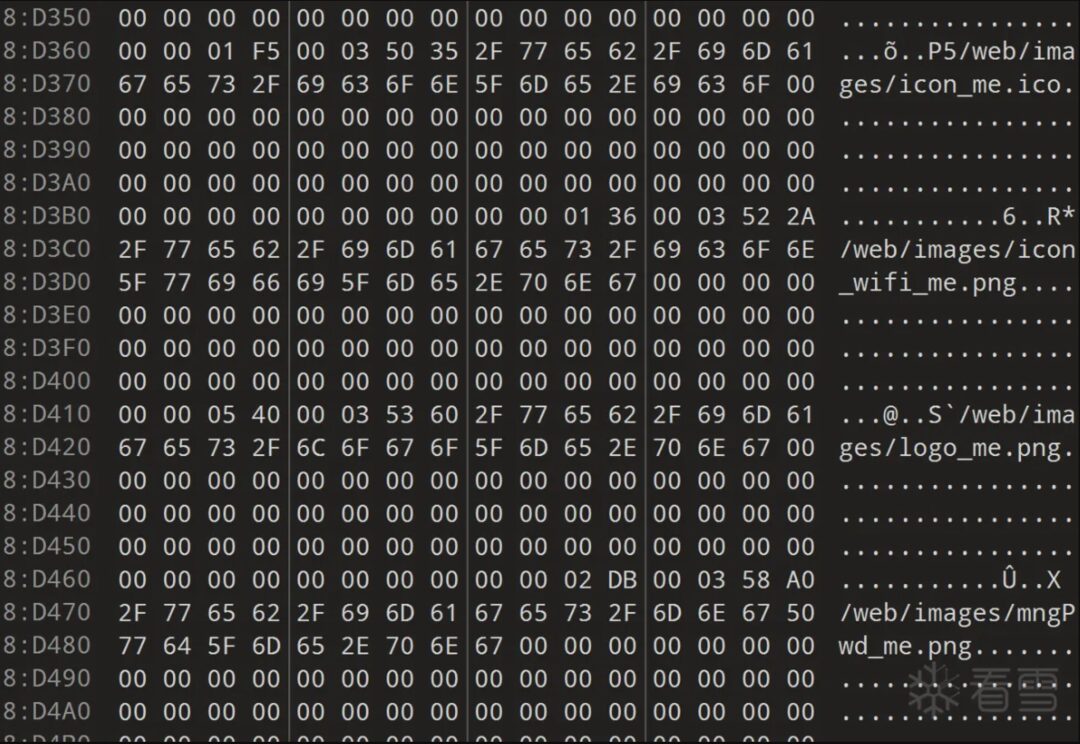
Therefore, we need to handle these cases differently:
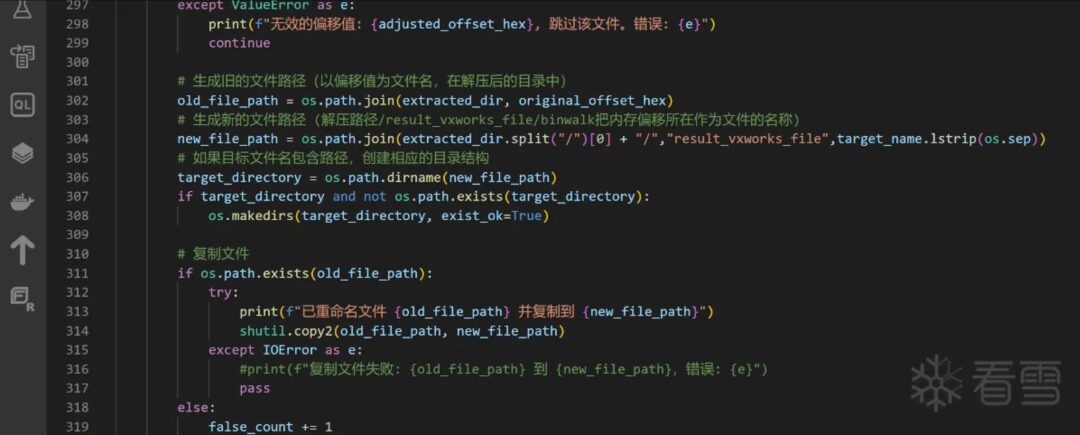
One-Click Automation of VxWorks File Extraction and Filename Recovery Code Implementation
Finally, here is the open-source code https://github.com/0xba1100n/vxfile_extractor
Effect images:
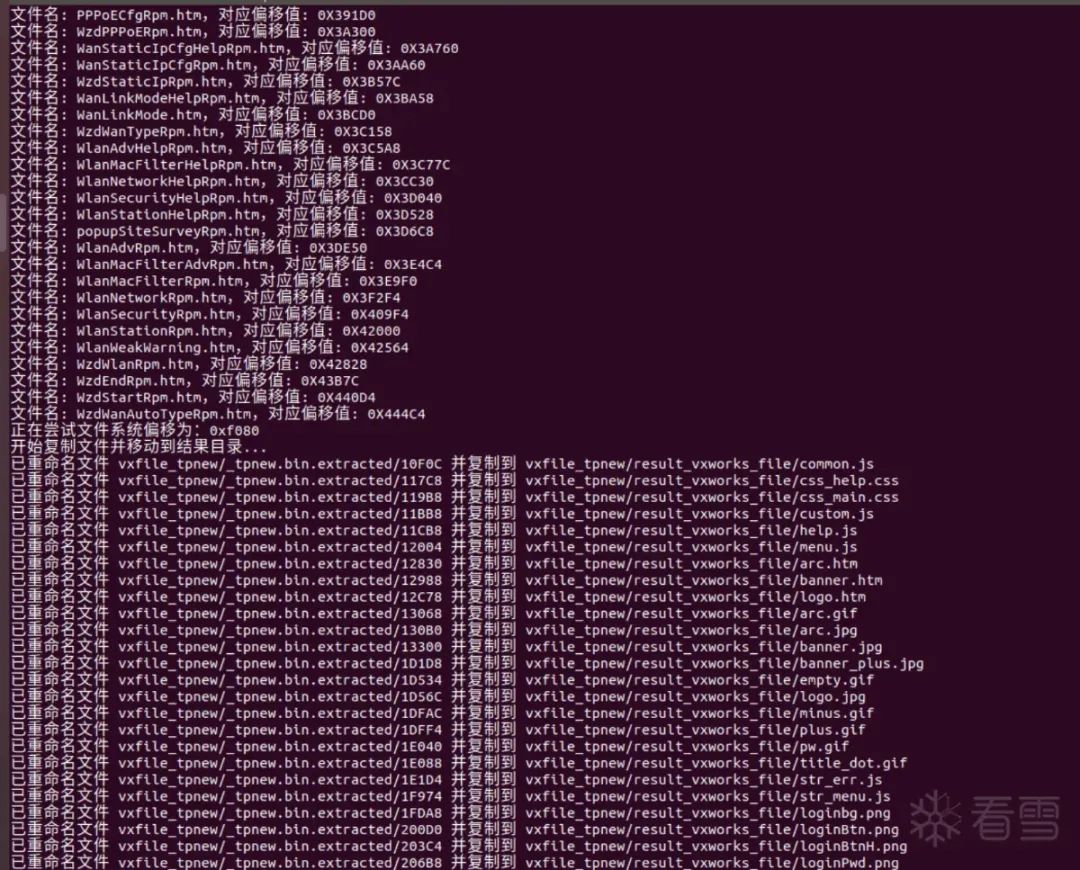
Vxfile Extractor V2 Improvements
Inspired by suggestions from WinMT in the comments, I improved related methods.
To enhance the versatility of the VxWorks firmware extraction script, the following solutions are adopted to avoid reliance on any hard-coded strings (such as IMG0 header) because relying on strings from binwalk is not robust enough—VxWorks has more than one firmware structure, and there may not always be a large area of matching 00 bytes (such as wr842nv3), so we need to think of more stable methods.
1. Finding Files Containing Offset Tables
After much thought, I decided to use this mixed approach (combining: precise but only applicable to firmware with http services + not very precise but versatile) to match, in order to balance precision and versatility.
For Firmware with Web Pages: Use Web Static Resource File References to Determine the Position of the File Offset Table
First, our targets for digging are almost all firmware with http pages, and currently, the web services of RTOS are static pages due to performance limitations. Inspired by the string matching of the front and back end of SaTC, we can actually obtain filename strings that exist and have their uniqueness from the perspective of file references.
This means we can eliminate those firmware that do not contain these 100% correct strings and consider them as firmware without a file offset table.
The steps involve first matching the resource reference statements in htm files, which contain “src=xxx”, to match the frontend files referenced. We can first execute in the area where binwalk has just unpacked, and the names are chaotic:
grep -r “src=” | grep -E “.(gif|jpg|js|css)”
Then, we will obtain some referenced static resource filenames with paths:
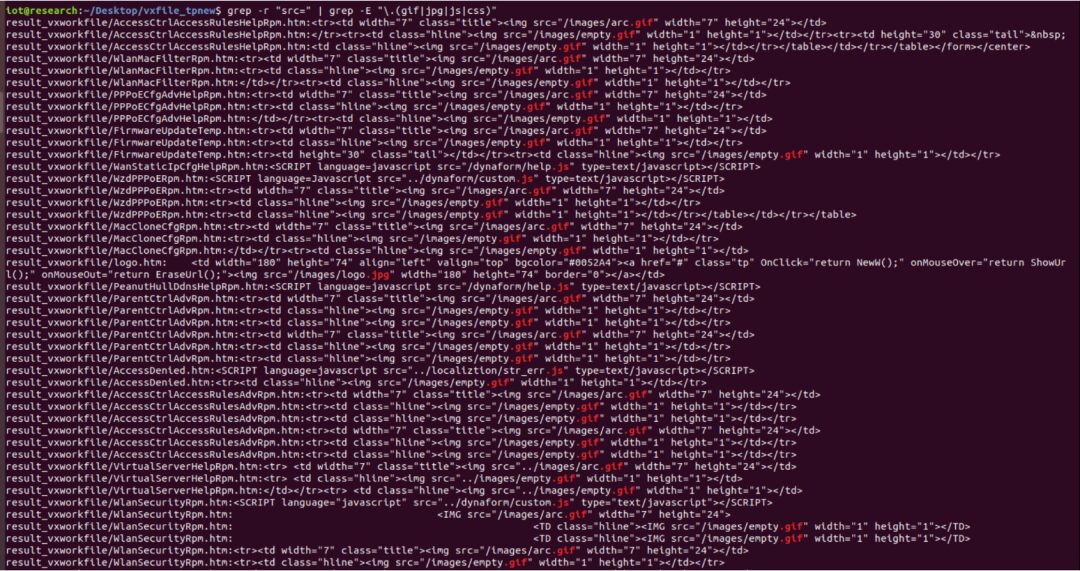
At this point, it is essential to clarify that if there exists a sufficiently rich table containing all offsets, it will contain a large number of these filenames. If we repeatedly match the results of each referenced filename and find overlaps, then there is likely a file offset table inside, as demonstrated by the following cases of two binwalk unpacked files that contain all referenced files, which are very likely to have tables.
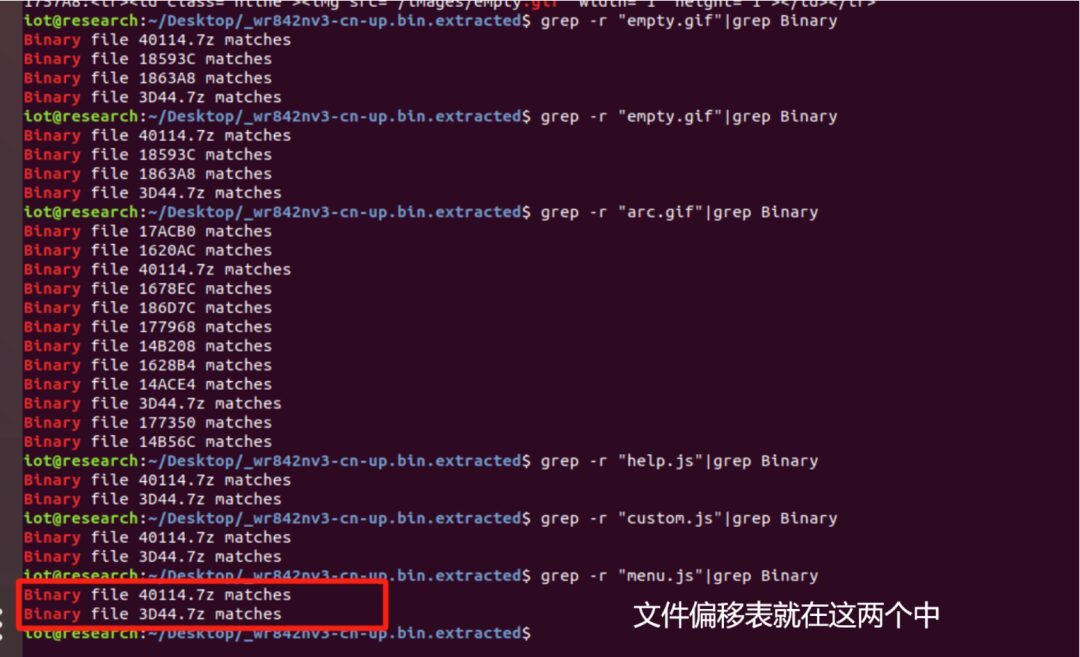
Using this method to determine the position of the table will achieve a true accuracy of 99.9%.
Moreover, the corresponding offset of this file should follow the principle of being small enough to be usable, as such a file offset table is used during initialization, and its base address must be small, close to the boot image.
Why did I think of this strategy? Because in some situations (like TP-Link’s WDR7600), if the referenced files have many without corresponding table entries, but using the grep suffix method still matches some binary files with partial strings, then that’s another matter; it seems there is no file offset table.
In this case, I cannot find a method to recover filenames, as there are only some incomplete records of filenames, let alone complete records of file offsets. It’s hard for a clever woman to cook without rice; if there’s a way, please let me know.
For Firmware Without Web Pages, or With Web Pages but No Static Resource References: MIME Type Exclusion + Internal File Name String Statistics + Calculating “Compact Regularity”
If we want to analyze VxWorks firmware without web pages, we need to come up with a more generalized method.
I have never seen completely web-free VxWorks firmware… Feel free to propose new suggestions or cases that this project cannot resolve; I would love to see more types of VxWorks firmware.
This method also tries not to rely on the relative positions of binwalk results and the IMG0 header. The current approach is more compatible than before.
If the user feels that the recovery effect of the previous method is not good, they can also use –fuzzmode to specify this method, which may yield unexpected results.
Moreover, the corresponding offset of this file should also follow the principle of being small enough to be usable, as such a file offset table is used during initialization, and its base address must be small, close to the boot image.
First, the script will obtain the names of all files in the decompressed folder:
Then, the script will exclude these MIME types, and no operations will be performed on files of these types:

After multiple fuzzy matching methods proved to be ineffective or insufficient, I came up with an idea.
First, clarify that the file offset table usually exists in files with the most .jpg, .png, etc. suffixes, so I use the following command to display the number of files with specific suffixes inside each file: strings_command = f”strings -t x -n 5 {file_path} | grep -E ‘\.jpg|\.png|\.js|\.cer|\.pem|\.bin'”
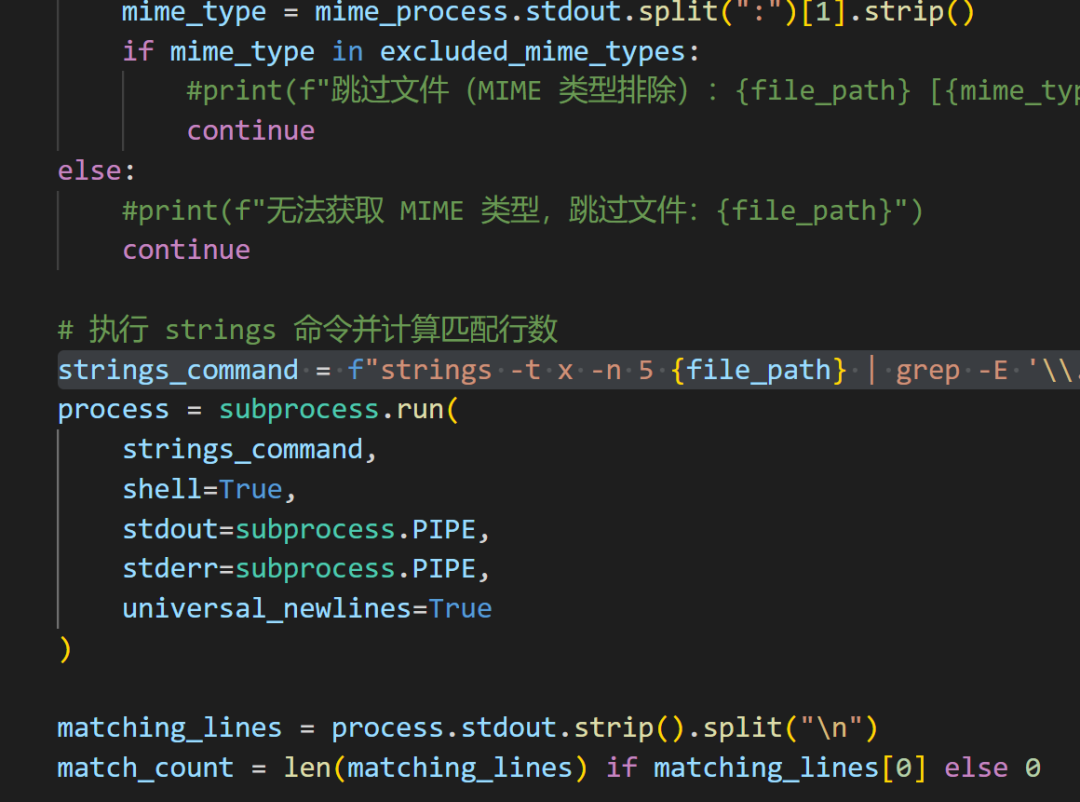
However, this method is overly idealized; in reality, files unpacked by binwalk may not always have the most such suffix files as the offset table, as sometimes a particular file is referenced multiple times, which can far exceed the offset table’s location.
So what’s a better method? This method is not baseless, as it is mostly applicable; it’s just a few cases where it fails.
Thus, I not only use the statistics of the number of matched internal filenames but also the offsets displayed by strings for each character.
If the offsets of each character are sometimes spaced by 0x30, sometimes by 0x38, sometimes by 0x28… then they appear quite neat.
On the contrary, if these characters do not exist in the file offset table, they are likely to be spaced by 0x11, 0x41, or even 0x191; in short, it will reflect the fluctuation of file offsets, chaotic.
How can we reflect this compactness and chaos?
If we strictly check the alignment of each string offset by 0x10 and 0x8, it is actually arbitrary, as the preceding file offset will introduce characters when matching strings, leading to offsets not adhering to that rule.
I thought of an idea: if the offsets of each character are organized, that is, nearly in arithmetic order.
Assuming the file offset table is 1, 2, 3, 4, 5, we can use the following method to filter out those files with many filenames that are not good.
1-2+3-4+5=3, 1-2+3-4+5-6=-3; this matches the format of the file offset table.
Meanwhile, some files may have 2-6+7-12=-9, taking the absolute value for comparison; this will reflect the more chaotic nature of the file offsets.
But it’s still not enough. First, 1-2+3-4+5=3, 1-2+3-4+5-6=-3 will gradually increase, so we need to use 2 as the period and divide by i/2.
(1-2+3-4+5)/3=1, (1-2+3-4+5-6)/3=-1.
This way, the compact regularity calculation function will oscillate within the range of +-1 and will not keep increasing. After experimenting, this improved the matching accuracy.
The implementation of the compact regularity calculation function is as follows:

And this function is still not enough. I encountered a situation.
Some functions have a small number of matched files, for example, only two filenames, but the file containing the offset table has 100 filenames.
Then, the two filenames will have a significant chance of gaining an advantage due to randomness. To prevent this randomness from leading to matching errors, we also need to consider the impact of the number of matched filenames mentioned earlier. How to combine these two methods? Here, I used a weighted average, multiplying the number of matched files by 0x1000 to bring their magnitude closer, and then using the compactness as the divisor since this value is smaller (should I call this the degree of discreteness? No matter, haha).
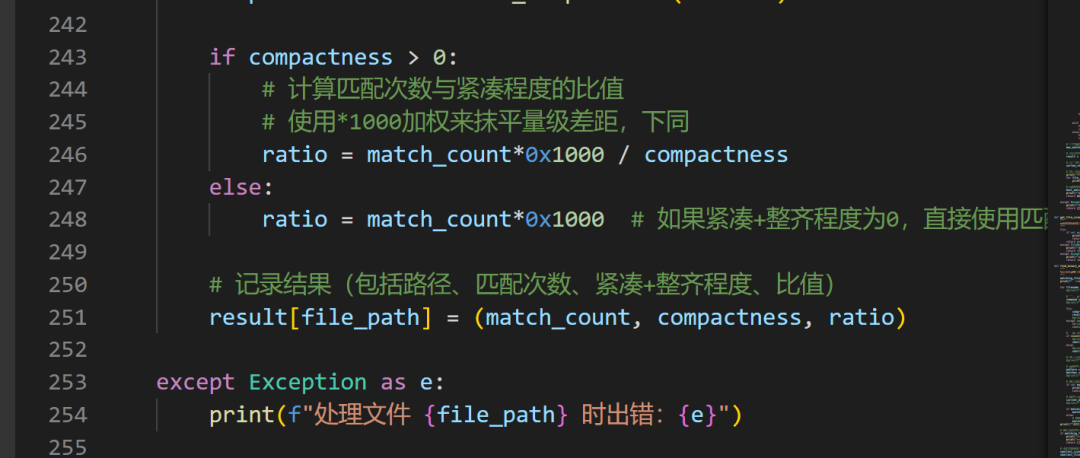
Additionally, files with a small number of matched filenames (less than or equal to 5) will be excluded from the string + grep rules, further eliminating randomness.
If the firmware has 5 or fewer files, it’s likely a super-mini firmware that can be manually analyzed. In that case, I really have no way; most firmware I’ve seen has at least 10 files, generally over 100 files.
Lastly, if there are schemes with the same compactness, there’s another method:

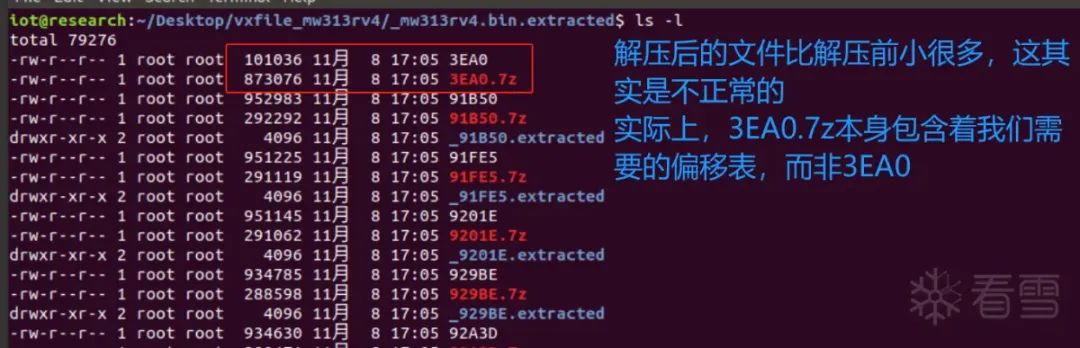
sorted_result = dict(sorted(result.items(), key=lambda item: (item[1][2], -len(item[0])), reverse=True))
This rule considers the length of the file path (which means 3EA0.7z has an advantage over 11451.7z) and, when the file path lengths are equal, sorts by character (which means 3EA0.7z has an advantage over 4191.7z).
This way, we can match the file offset table closest to the initialization uImage part of the firmware.
2. Finding the Offset of the File Offset Table Inside the File (That’s a mouthful _(:з」∠)_)
Later, I found that searching for the file offset table within the file by repeatedly matching 0x100 null bytes and then searching for the next non-null byte is not reliable, as there may not be a large area of matching 00 bytes (like wr842nv3):
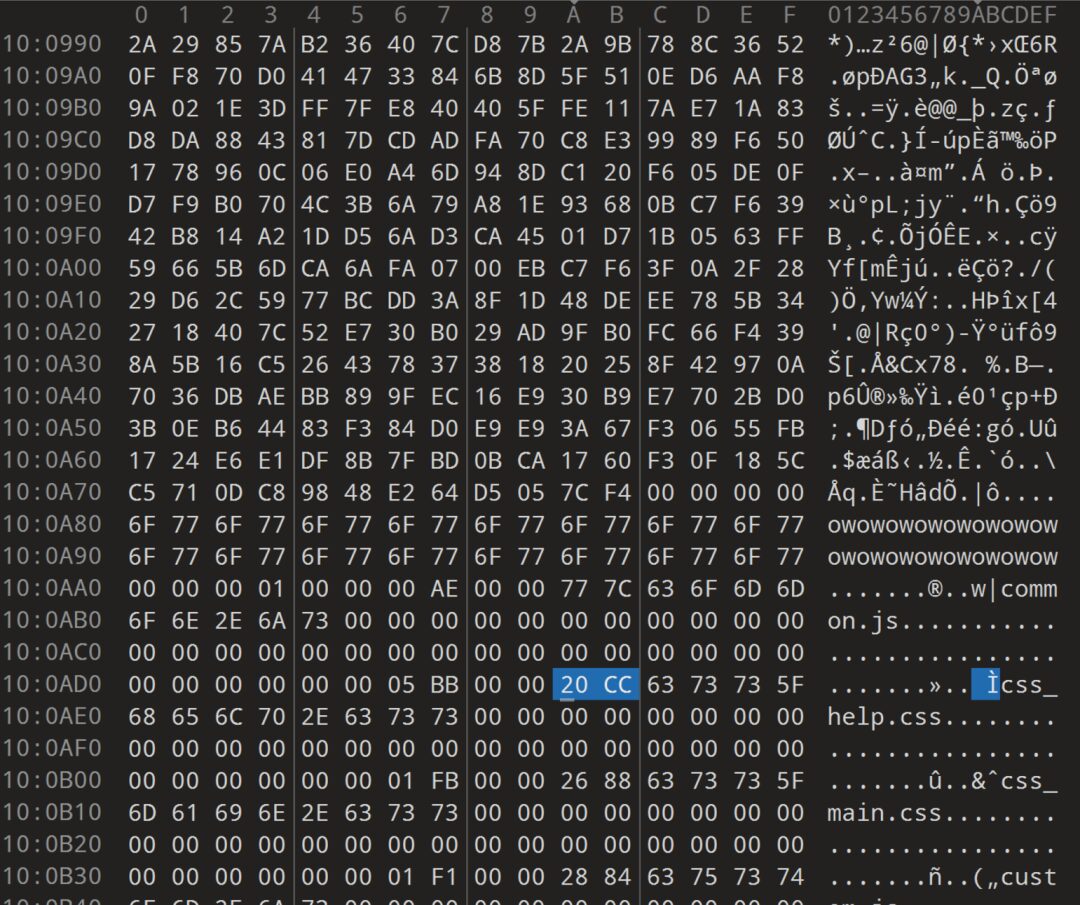
As shown, this is where the program .text content seamlessly fits with the file offset table, causing the v1 file offset table extraction method to fail.
Now that we have obtained a file containing an offset table, we can first match the positions of strings with the following file suffixes in the file where the offset table is located. Using strings not only allows for matching but also conveniently displays offsets.
◆Image Files
◆.jpg
◆.png
◆Web and Style Files
◆.js
◆.css
◆.htm
◆Configuration Files
◆.xml
◆Certificate and Key Files
◆.cer
◆.pem
◆Binary Files
◆.bin
Then, the length must be at least 5, with the matching command and displayed strings as follows:
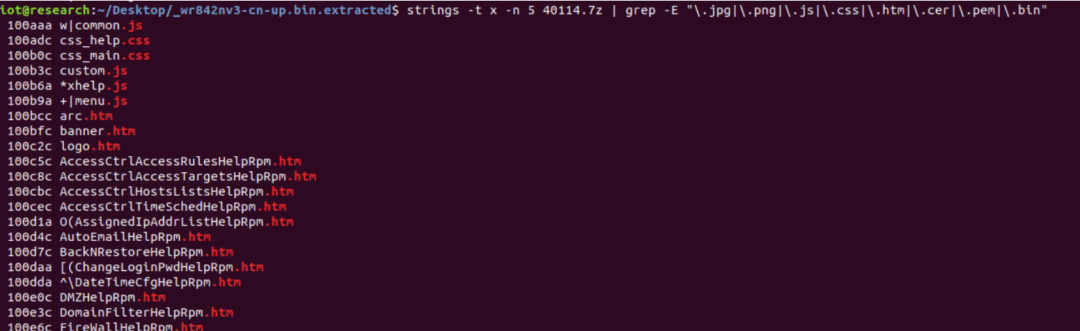
Return the first line, which is most likely the offset of the table entry in the file.
strings -t x -n 5 40114.7z | grep -E “.jpg|.png|.js|.css|.htm|.cer|.pem|.bin” | head -n 1
This way, we obtain the most likely offset of the file offset table in the file, such as here at 0x100aaa.
To avoid omissions, the obtained offset value will also be reduced by 0x50, and then the previously mentioned filename matching detection will be performed, so that even if there are files that do not have the above suffixes and are at the beginning, they will be matched.
3. Finding the Basic Offset of the Filesystem
Next, I improved the method for determining the filesystem offset, no longer relying on string positions but calculating attempts from start to end.
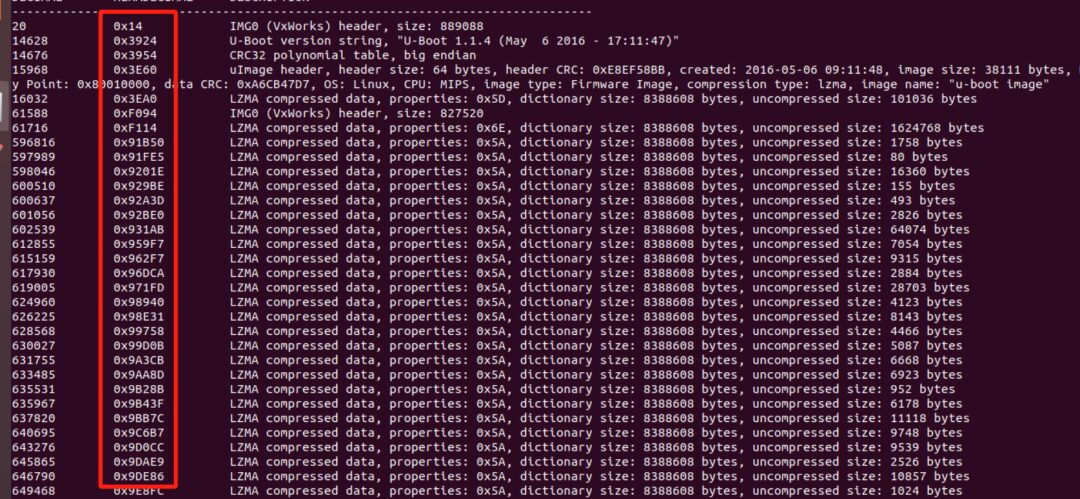
You might think this method is too simple; in some situations, a certain incorrect offset + file offset table offset just happens to correspond to the real file.
However, as previously mentioned, if ten consecutive file offsets are incorrect, the matching will exit, so even if a certain offset is correct, it will not lead to continuous renaming of files (unless it’s an extremely unlikely coincidence).

That’s the main changes in version v2.

Kanxue ID: It’s a balloon
https://bbs.kanxue.com/user-home-869206.htm
# Previous Recommendations
1、PWN Introduction – SROP Apprenticeship
2、A Variant of APC Injection Type Gamarue Virus
3、Brutal Fuzz: Improving Performance
4、Discussion on Several Injection Methods for Android, Open Source Injection Module Implementation
5、2024 KCTF Water Margin – Anti-Obfuscation

Share the Ball

Like the Ball

Watching the Ball

Click to read the original text for more