The Linux system generally has four main parts:
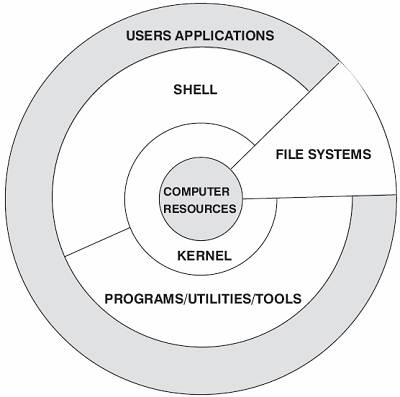
Kernel, shell, file system, and applications. The kernel, shell, and file system together form the basic operating system structure, allowing users to run programs, manage files, and use the system. A part of the hierarchy is shown in Figure 1-1.
1. Linux Kernel
The kernel is the core of the operating system, with many basic functions. It is responsible for managing system processes, memory, device drivers, files, and network systems, determining the performance and stability of the system.
The Linux kernel consists of the following parts: memory management, process management, device drivers, file systems, and network management, etc. As shown in the figure:
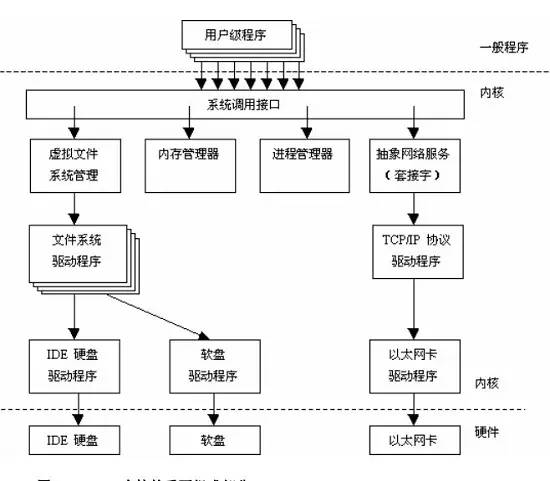
Figure 1
The system call interface (SCI) layer provides mechanisms for executing function calls from user space to the kernel. This interface depends on the architecture and can vary even within the same family of processors. The SCI is essentially a very useful service for function call multiplexing and demultiplexing. You can find the implementation of SCI in ./linux/kernel and the architecture-dependent parts in ./linux/arch.
2. Memory Management
For any computer, its memory and other resources are limited. To meet the large demand for memory from applications, Linux adopts a memory management method called “virtual memory.” Linux divides memory into manageable “memory pages” (which are generally 4KB for most architectures). Linux includes ways to manage available memory and the hardware mechanisms used for physical and virtual mapping.
However, memory management does not only manage 4KB buffers. Linux provides an abstraction for 4KB buffers, such as the slab allocator. This memory management model uses 4KB buffers as a base, then allocates structures from them and tracks the usage of memory pages, such as which memory pages are full, which pages are not fully used, and which pages are empty. This allows the model to dynamically adjust memory usage based on system needs.
To support multiple users using memory, there can be situations where available memory is exhausted. For this reason, pages can be swapped out of memory and placed on disk. This process is called swapping, as pages are swapped from memory to hard disk. The source code for memory management can be found in ./linux/mm.
3. Process Management
A process is actually a running entity of a specific application. In a Linux system, multiple processes can run simultaneously, and Linux achieves “multitasking” by alternately running these processes in short time intervals. This short time interval is called a “time slice,” and the method of allowing processes to run in turn is called “process scheduling,” with the scheduling program referred to as the scheduler.
Process scheduling controls the access of processes to the CPU. When it is necessary to choose the next process to run, the scheduler selects the most deserving process to run. Runnable processes are those that are simply waiting for CPU resources; if a process is waiting for other resources, it is considered a non-runnable process. Linux uses a relatively simple priority-based process scheduling algorithm to select new processes.
Through the multitasking mechanism, each process can be thought of as having exclusive access to the computer, simplifying program writing. Each process has its own separate address space and can only be accessed by that process, which prevents interference between processes and the potential harm that “bad” programs can cause to the system. To accomplish specific tasks, it may be necessary to integrate the functions of two programs, such as one program outputting text while another sorts the text. For this purpose, the operating system also provides inter-process communication mechanisms to help complete such tasks. Common inter-process communication mechanisms in Linux include signals, pipes, shared memory, semaphores, and sockets.
The kernel provides an application programming interface (API) through SCI to create a new process (fork, exec, or Portable Operating System Interface [POSIX] functions), stop processes (kill, exit), and facilitate communication and synchronization between them (signal or POSIX mechanisms).
4. File System
Unlike operating systems like DOS, the separate file systems in Linux are not identified by drive letters or names (such as A: or C:). Instead, like UNIX operating systems, Linux combines separate file systems into a hierarchical tree structure, represented by a single entity. Linux mounts new file systems onto a directory through an operation called “mounting,” allowing different file systems to combine into a whole. An important feature of the Linux operating system is that it supports many different types of file systems. The most commonly used file system in Linux is Ext2, which is also the native file system of Linux. However, Linux can also support various file systems like FAT, VFAT, FAT32, MINIX, etc., allowing for easy data exchange with other operating systems. Due to Linux’s support for many different file systems, they are organized into a unified virtual file system.
The Virtual File System (VFS) hides the specific details of various hardware, separating file system operations from the implementation details of different file systems, providing a unified interface for all devices. VFS offers dozens of different file systems. The virtual file system can be divided into logical file systems and device drivers. Logical file systems refer to the file systems supported by Linux, such as ext2, fat, etc., while device drivers refer to the device driver modules written for each hardware controller.
The virtual file system (VFS) is a very useful aspect of the Linux kernel as it provides a common interface abstraction for file systems. VFS provides an exchange layer between the SCI and the file systems supported by the kernel. That is, VFS provides an exchange layer between users and file systems.
VFS provides an exchange layer between users and file systems:
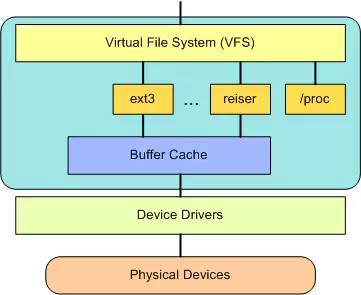
Above the VFS is a general API abstraction for functions such as open, close, read, and write. Below the VFS is the file system abstraction that defines how the upper-level functions are implemented. They are plugins for specific file systems (over 50). The source code for file systems can be found in ./linux/fs.
Below the file system layer is the buffer cache, which provides a common function set for the file system layer (independent of specific file systems). This cache layer optimizes access to physical devices by temporarily holding data (or pre-reading data so that it is available when needed). Below the buffer cache is the device driver, which implements the interface for specific physical devices.
Therefore, users and processes do not need to know the type of file system where a file resides; they can use it just like using files in the Ext2 file system.
5. Device Drivers
Device drivers are a major part of the Linux kernel. Similar to other parts of the operating system, device drivers run in a high-privilege processor environment, allowing direct manipulation of hardware. However, because of this, any error in a device driver can lead to a system crash. Device drivers actually control the interaction between the operating system and hardware devices.
Device drivers provide a set of abstract interfaces that the operating system can understand to complete interactions with the operating system, while the specific operational details related to hardware are handled by the device driver. Generally, device drivers are related to the control chips of the devices. For example, if the computer’s hard disk is a SCSI hard disk, the SCSI driver is needed instead of the IDE driver.
6. Network Interface (NET)
Provides access to various network standards and support for various network hardware. Network interfaces can be divided into network protocols and network drivers. The network protocol part is responsible for implementing every possible network transmission protocol. The TCP/IP protocol is well-known as the standard protocol for the Internet, as well as the de facto industrial standard.
The network implementation in Linux supports BSD sockets and all TCP/IP protocols. The network part of the Linux kernel consists of BSD sockets, network protocol layers, and network device drivers. Network device drivers are responsible for communicating with hardware devices, and each possible hardware device has a corresponding device driver.
7. Linux Shell
The shell is the user interface of the system, providing an interface for users to interact with the kernel. It receives user input commands and sends them to the kernel for execution, acting as a command interpreter. Additionally, the shell programming language has many characteristics of general programming languages, and shell programs written in this language have the same effect as other applications.
Currently, there are several main versions of the shell.
1. Bourne Shell: Developed by Bell Labs. 2. BASH: GNU’s Bourne Again Shell, the default shell on GNU operating systems, and most Linux distributions use this shell. 3. Korn Shell: An evolution of the Bourne Shell, compatible with most of its content. 4. C Shell: The BSD version of the SUN company’s Shell.
8. Linux File System
The file system is the organization method for files stored on disks and other storage devices. The Linux system can support many currently popular file systems, such as EXT2, EXT3, FAT, FAT32, VFAT, and ISO9660.
8.1 File Types
The main file types under Linux are:
1) Regular files: C language source code, SHELL scripts, binary executable files, etc. These can be divided into plain text and binary. 2) Directory files: directories, the only place to store files. 3) Link files: files that point to the same file or directory. 4) Device files: related to system peripherals, usually under /dev. These can be divided into block devices and character devices.
5) Pipe (FIFO) files: A way to provide communication between processes. 6) Socket files: This file type is related to network communication.
You can use commands like ls -l, file, and stat to view file types and related information.
8.2 Linux Directory
The file structure is the organization method for files stored on disks and other storage devices. This is mainly reflected in the organization of files and directories.
Directories provide a convenient and efficient way to manage files.
Linux uses a standard directory structure, and during installation, the installation program has already created a file system and a complete, fixed directory composition, specifying the role of each directory and the types of files within them.
The complete directory tree can be divided into smaller parts, which can be stored separately on their own disks or partitions. This way, relatively stable parts and frequently changing parts can be stored separately on different partitions, facilitating backup or system management. The main parts of the directory tree include root, /usr, /var, /home, etc. (Figure 2). This layout facilitates sharing certain parts of the file system between Linux computers.
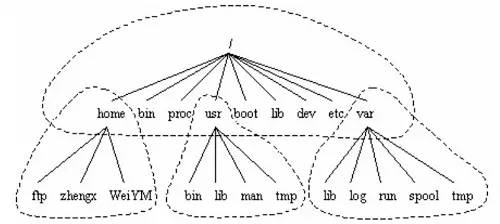
Figure 2
Linux adopts a tree structure. The top level is the root directory, and all other directories are generated from the root directory.
Microsoft’s DOS and Windows also adopt a tree structure, but in DOS and Windows, the root of such a tree structure is the drive letter of the disk partition. The number of partitions corresponds to the number of tree structures, and their relationships are parallel. The topmost level is different disks (partitions), such as C, D, E, F, etc.
However, in Linux, regardless of how many disk partitions the operating system manages, there is only one directory tree. Structurally, the tree directories on each disk partition are not necessarily parallel.
8.3 Linux Disk Partitions
1. Primary, Extended, and Logical Partitions:
Linux partitions differ from Windows. Both hard disks and partitions in Linux are represented as devices.
There are three types of disk partitions: primary partitions, extended partitions, and logical partitions.
The main types of disk partitions are primary partitions (Primary Partition) and extended partitions (Extended Partition), with the total number of primary and extended partitions not exceeding four.
Primary Partition: Can be used immediately but cannot be partitioned further.
Extended Partition: Must be partitioned again before it can be used, meaning it must undergo secondary partitioning.
Logical Partition: A partition created from an extended partition. Logical partitions have no numerical limit.
The extended partition is merely a “container” for logical partitions, and only primary and logical partitions are used for data storage.
2. Identifying Hard Disk Partitions in Linux
Hard disk partitions are generally identified using /dev/hd[a-z]X or /dev/sd[a-z]X, where [a-z] represents the hard disk number, and X represents the partition number within the hard disk.
The block number identifier for the entire hard disk partition: In Linux, different hard disks are identified as hda, hdb, sda, sdb, etc.;
Where:
IDE interface hard disks are represented as /dev/hda1, /dev/hdb, etc.;
SCSI interface hard disks and SATA interface hard disks are represented as /dev/sda, /dev/sdb, etc.;
Partitions within a hard disk: If the value of X is 1 to 4, it indicates the primary partition (including extended partitions); logical partitions start from 5, for example, /dev/hda5 is definitely a logical partition.
For example:
Using hda1, hda2, hda5, hda6 to identify different partitions. Here, the letter a represents the first hard disk, b represents the second hard disk, and so on. The number 1 represents the first partition of a hard disk, 2 represents the second partition, and so on. 1 to 4 correspond to primary partitions (Primary Partition) or extended partitions (Extended Partition). Starting from 5, they correspond to logical partitions (Logical Partition) of the hard disk. Even if a hard disk has only one primary partition, logical partitions will still be numbered starting from 5, which should be noted.
In summary: To identify a hard disk partition, first confirm which hard disk it is on, and then confirm which partition it is on that hard disk.
For identifiers like /dev/hda, we can check whether it is /dev/hda or /dev/hdb in Linux using fdisk -l;
[root@localhost ~]# fdisk -l
Disk /dev/hda: 80.0 GB, 80026361856 bytes
255 heads, 63 sectors/track, 9729 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
/dev/hda1 * 1 970 7791493+ 7 HPFS/NTFS
/dev/hda2 971 9729 70356667+ 5 Extended
/dev/hda5 971 2915 15623181 b W95 FAT32
/dev/hda6 2916 4131 9767488+ 83 linux
/dev/hda7 4132 5590 11719386 83 linux
/dev/hda8 5591 6806 9767488+ 83 linux
/dev/hda9 6807 9657 22900626 83 linux
/dev/hda10 9658 9729 578308+ 82 linux swap / Solaris
Please note the first line, Disk /dev/hda: 80.0 GB, 80026361856 bytes, which indicates that the machine has only one hard disk device /dev/hda with a size of 80.0G; below are the partitions of the hard disk, each partition has detailed information, which will not be elaborated here;
The relationship between disk partitions and directories in Linux is as follows:
– Any partition must be mounted to a directory.
– Directories are logical distinctions. Partitions are physical distinctions.
– Disk Linux partitions must be mounted to a specific directory in the directory tree to perform read and write operations.
– The root directory is where all Linux files and directories reside, requiring a mounted disk partition.
8.4 Functions of Major Linux Directories
/bin Binary executable commands /dev Device special files /etc System management and configuration files /etc/rc.d Startup configuration files and scripts /home User home directory base, for example, the home directory of user user is /home/user, which can be represented as ~user /lib Standard program design library, also known as dynamic link shared library, serving a similar function as .dll files in Windows /sbin System management commands, where programs for system administrators are stored /tmp Public temporary file storage point /root System administrator’s home directory (the privileged class) /mnt This directory is provided by the system for users to temporarily mount other file systems. /lost+found This directory is usually empty; files left behind due to abnormal system shutdown and “homeless” (similar to .chk in Windows) are placed here /proc A virtual directory that maps system memory. You can directly access this directory to obtain system information. /var An overflow area for some large files, such as various service log files /usr The largest directory, where almost all applications and files needed are located. It contains: /usr/X11R6 Directory for X window /usr/bin Numerous applications /usr/sbin Some management programs for superusers /usr/doc Linux documentation /usr/include Header files needed for developing and compiling applications under Linux /usr/lib Common dynamic link libraries and configuration files for software packages /usr/man Help documents /usr/src Source code, the Linux kernel source code is located in /usr/src/linux /usr/local/bin Locally added commands /usr/local/lib Locally added libraries
8.5 Linux File System
The file system refers to the physical space where files exist. Each partition in the Linux system is a file system, each with its own directory hierarchy. Linux will form a total directory hierarchy of the system in a certain way from these separate file systems belonging to different partitions. The operation of an operating system cannot be separated from file operations, so it must have and maintain its own file system.
-
File System Types:
ext2: A commonly used file system in early Linux ext3: An upgraded version of ext2 with logging capabilities RAMFS: A memory file system, very fast NFS: Network File System, invented by SUN, mainly used for remote file sharing MS-DOS: MS-DOS file system VFAT: The file system used by Windows 95/98 FAT: The file system used by Windows XP NTFS: The file system used by Windows NT/XP HPFS: The file system used by OS/2 PROC: Virtual process file system ISO9660: The file system used by most CDs ufsSun: The file system used by OS NCPFS: The file system used by Novell servers SMBFS: Samba’s shared file system XFS: An advanced logging file system developed by SGI, supporting very large files JFS: The logging file system used by IBM’s AIX ReiserFS: A file system based on balanced tree structures udf: A rewritable data CD file system
2. File System Characteristics:
After partitioning the disk, it also needs to be formatted (format) before the operating system can use this partition. The purpose of formatting is to create a file system format that can be used by the operating system (i.e., the file system types mentioned above).
Each operating system can use different file systems. For example, Microsoft’s operating systems prior to Windows 98 mainly utilized the FAT (or FAT16) file system, while versions of Windows 2000 and later have the so-called NTFS file system. The proper file system for Linux is Ext2 (Linux second extended file system, ext2fs). Additionally, by default, Windows operating systems do not recognize Linux’s Ext2.
In traditional applications of disks and file systems, a partition can only be formatted into one file system, so we can say that a filesystem is a partition. However, due to the utilization of new technologies, such as LVM and software RAID, these technologies can format a partition into multiple file systems (e.g., LVM) or combine multiple partitions into one file system (LVM, RAID)! Therefore, we no longer refer to formatting as targeting a partition; we can usually call a mountable data a file system rather than a partition!
So how does the file system operate? This relates to the file data of the operating system. In newer operating systems, file data typically contains many attributes in addition to the actual file content, such as file permissions (rwx) and file attributes (owner, group, time parameters, etc.). The file system typically stores these two parts of data in different blocks, with permissions and attributes placed in the inode, while the actual data is placed in the data block. Additionally, there is a superblock that records overall information about the file system, including the total number of inodes and blocks, usage, remaining amounts, and so on.
For a disk partition, once it is designated as the corresponding file system, the entire partition is divided into blocks of sizes 1024, 2048, and 4096 bytes. Depending on the block usage, they can be divided into:
-
Superblock: This is the first block of the entire file system, including basic information about the entire file system, such as block size, total number of inodes/blocks, usage, remaining amount, pointers to inode and data block spaces, and other related information.
-
Inode Block (File Index Node): File system index, records file attributes. It is the most basic unit of the file system, serving as a bridge to connect any subdirectory or file. Each subdirectory and file has a unique inode block. It contains basic attributes of files in the file system (length, creation and modification time, permissions, ownership), and information about where the data is stored. In Linux, you can view file inode information using the “ls -li” command. Hard links and source files share the same inode.
-
Data Block: Actual records of file content. If a file is too large, it may occupy multiple blocks. To improve directory access efficiency, Linux also provides a dentry structure that expresses the relationship between paths and inodes. It describes path information and connects to the inode, including various directory information, and points to the inode and superblock.
Just like a book has a cover, a table of contents, and a main text, in the file system, the superblock is equivalent to the cover, from which you can glean basic information about the book; the inode block is like the table of contents, from which you can find the location of various chapters; and the data blocks are equivalent to the main text, recording specific content.
The standard Linux file systems (such as ext2, 3, etc.) will delineate superblocks, inode Table blocks, and data area blocks during hard disk partitioning. A file consists of a superblock, inode, and data area blocks. The inode contains file attributes (such as read/write attributes, owner, etc., as well as pointers to data blocks), while the data area blocks are the file’s content. When viewing a file, the system first checks the inode table for file attributes and data storage points, and then reads data from the data blocks.
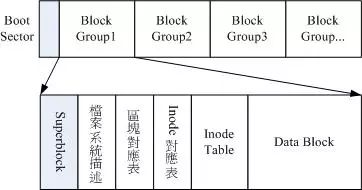
Diagram of the ext2 file system
We will illustrate the inode and block areas with a diagram. As shown below, the file system first formats the inode and block areas. Assuming the attributes and permission data of a certain file are placed in inode 4 (in the small square in the diagram), and this inode records that the actual data is placed in blocks 2, 7, 13, and 15, the operating system can arrange the reading order of the disk based on this, allowing all four blocks of content to be read at once! Thus, data reading occurs as indicated by the arrows in the diagram.
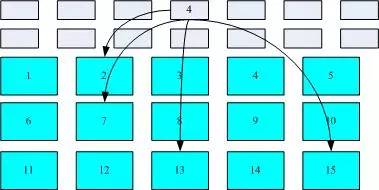
Diagram of inode/block data access
This method of data access is called indexed allocation. Are there other commonly used file systems for comparison? Yes, the commonly used flash drives generally use the FAT format. The FAT file system does not have inodes, so it cannot read all the blocks of a file at once. Each block number is recorded in the previous block, and its reading method is illustrated in the diagram below:
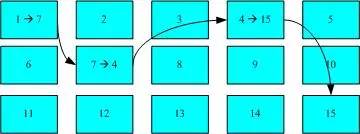
Diagram of FAT file system data access
In the diagram, we assume that the file’s data is sequentially written to blocks 1->7->4->15, but this file system cannot know all four block numbers at once. It must read each block one by one to find the next block. If the data of the same file is written too dispersedly, the disk reading head will not be able to read all the data in one pass, thus requiring multiple rotations to completely read the content of this file!
We often hear about “defragmentation”; the need for defragmentation arises because the blocks of file data are too dispersed, causing poor reading efficiency. At this time, defragmentation can be used to gather the blocks belonging to the same file together, making data reading easier! Naturally, the FAT file system requires frequent defragmentation, whereas Ext2 does not require frequent defragmentation. However, if the file system is used for too long, often deleting/editing/adding files, it may still lead to data dispersion issues, and defragmentation may be needed. However, honestly, I have not performed defragmentation on Ext2/Ext3 file systems in Linux! It seems unnecessary! ^_^
You can use the ln command to create a new link to an existing file without copying its content. There are soft links and hard links, each with its characteristics:
Hard Links: A copy of the file where the original file name and link file name point to the same physical address. Directories cannot have hard links; hard links cannot span file systems (cannot cross different partitions). There is only one copy of the file on the disk, saving disk space;
Modifying one will simultaneously modify the linked file. If any one of them is deleted, the others remain unaffected.
Since deleting a file can only succeed when there is a unique connection to the same inode, it can prevent unnecessary accidental deletions.
Symbolic Links (Soft Links): Created using the ln -s command, a symbolic link is a special file in Linux, and as a file, its data is the path name of the file it links to. This is similar to shortcuts in Windows.
Of course, deleting this link will not affect the source file, but the usage and references to the link file are directly calling the source file.
The specific relationships can be seen in the diagram below:
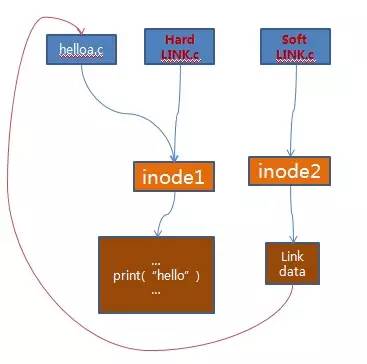
Figure 5: Differences between soft links and hard links
From the diagram, we can see the differences between hard links and soft links:
1: The inode numbers of the original file and the new file are consistent for hard links, while for soft links, they are different.
2: Deleting the original file will make the soft link unusable, while hard links remain unaffected.
3: Modifying the original file will also modify the content of the soft and hard link files since they all point to the same file content.
8.9 File Directory Management Commands
Disk and File Space: fdisk df du
File Directory and Management: cd pwd mkdir rmdir ls cp rm mv
View File Content: cat, tac, more, less, head, tail
File Directory and Permissions: chmod chown chgrp umask
File Search: which, whereis, locate, find, find
9. Linux Applications
A standard Linux system generally includes a set of application programs, which includes text editors, programming languages, X Window, office suites, Internet tools, and databases.
10. Linux Kernel Parameter Optimization
Kernel parameters are an interface for interaction between users and the system kernel. Through this interface, users can dynamically update kernel configurations while the system is running, and these kernel parameters exist through the Linux Proc file system. Therefore, performance optimization of Linux can be achieved by adjusting the Proc file system.
Source: huangguisu
Link: http://blog.csdn.net/hguisu/article/details/6122513
Disclaimer: The content and images are sourced from the internet, and the copyright belongs to the original author. If your original copyright is infringed, please let us know, and we will delete the relevant content as soon as possible.
Free Trial Class Registration at Daren!
 Long press the QR code to register for free
Long press the QR code to register for free

Full course taught by top-notch instructors, analyzing industry trends and employment prospects,
helping you easily get started and become a tech expert faster!
Recommended Reading
-
Employment Report | How Close Are You to a Monthly Salary of 20000?
-
A Daren student without a formal background doubled their salary!
-
Breaking News! For 10 consecutive days, 82 job fairs; all the good jobs you want are here.
-
From Beginner to Giving Up… Is Self-learning Programming Really That Hard?