Necessary Components Before Getting Started
-
Powerful Raspberry Pi (e.g., Model 4)
-
Official Raspberry Pi camera, or: USB webcam
-
Power connection: micro USB cable and USB adapter
What is Text Recognition (OCR) and How Does it Work on Raspberry Pi?
Installing Tesseract OCR Library
sudo apt install tesseract-ocr
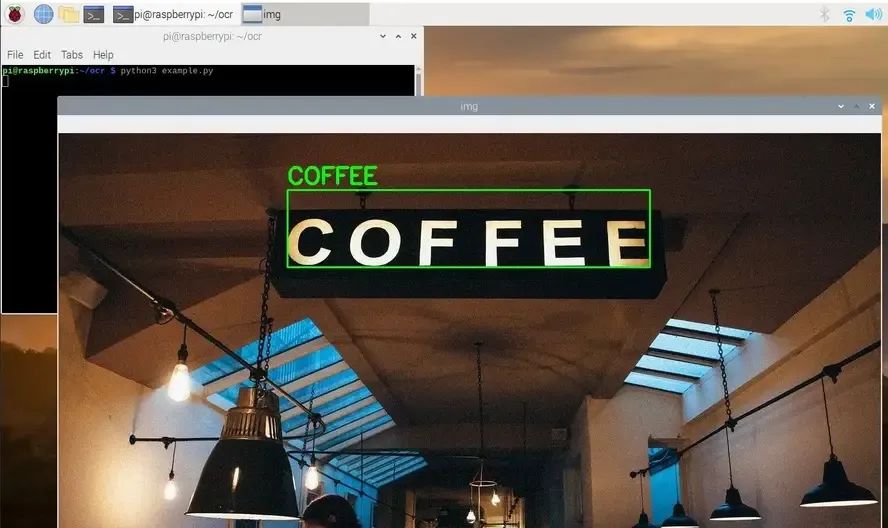
wget https://tutorials-raspberrypi.de/wp-content/uploads/coffee-ocr.jpgtesseract coffee-ocr.jpg stdoutWarning: Invalid resolution 0 dpi. Using 70 instead.Estimating resolution as 554COFFEEpip3 install opencv-python pillow pytesseract imutils numpymkdir ocrcd ocrsudo nano example.pyimport cv2
import pytesseract
import numpy as np
from pytesseract import Output
img_source = cv2.imread('images/coffee.jpg')
def get_grayscale(image):
return cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
def thresholding(image):
return cv2.threshold(image, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)[1]
def opening(image):
kernel = np.ones((5, 5), np.uint8)
return cv2.morphologyEx(image, cv2.MORPH_OPEN, kernel)
def canny(image):
return cv2.Canny(image, 100, 200)
gray = get_grayscale(img_source)
thresh = thresholding(gray)
opening = opening(gray)
canny = canny(gray)
for img in [img_source, gray, thresh, opening, canny]:
d = pytesseract.image_to_data(img, output_type=Output.DICT)
n_boxes = len(d['text'])
# back to RGB
if len(img.shape) == 2:
img = cv2.cvtColor(img, cv2.COLOR_GRAY2RGB)
for i in range(n_boxes):
if int(d['conf'][i]) > 60:
(text, x, y, w, h) = (d['text'][i], d['left'][i], d['top'][i], d['width'][i], d['height'][i])
# don't show empty text
if text and text.strip() != "":
img = cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
img = cv2.putText(img, text, (x, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 1.2, (0, 255, 0), 3)
cv2.imshow('img', img)
cv2.waitKey(0)-
Import libraries (lines 1-4)
-
Load image (line 5), adjust the path as needed!
-
Preprocessing functions to convert to grayscale (lines 9-23)
-
Line 32: Here we extract any data (text, coordinates, scores, etc.)
-
In order to color the boxes later if necessary, we convert the grayscale image back to an image with color channels (lines 36-37)
-
From line 39, we color the boxes for scores above 60.
-
For this, we extract text, starting coordinates, and box sizes in line 41.
-
We only draw boxes if non-empty text is detected (lines 43-45).
-
Then we run the script and wait for the escape key to be pressed (lines 47/48).
python3 example.pyRecognizing Text in Real-Time Images with Raspberry Pi Camera
sudo nano ocr_camera.pyimport cv2
import pytesseract
from pytesseract import Output
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_BUFFERSIZE, 1)
while True:
# Capture frame-by-frame
ret, frame = cap.read()
d = pytesseract.image_to_data(frame, output_type=Output.DICT)
n_boxes = len(d['text'])
for i in range(n_boxes):
if int(d['conf'][i]) > 60:
(text, x, y, w, h) = (d['text'][i], d['left'][i], d['top'][i], d['width'][i], d['height'][i])
# don't show empty text
if text and text.strip() != "":
frame = cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
frame = cv2.putText(frame, text, (x, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (0, 0, 255), 3)
# Display the resulting frame
cv2.imshow('frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# When everything done, release the capture
cap.release()
cv2.destroyAllWindows()-
In lines 5-6, we define the camera instead of a fixed image. The camera must be connected and recognized.
-
In line 10, we read the current frame.
-
Here we omit preprocessing steps, but these can easily be inserted (in line 11).
python3 ocr_camera.py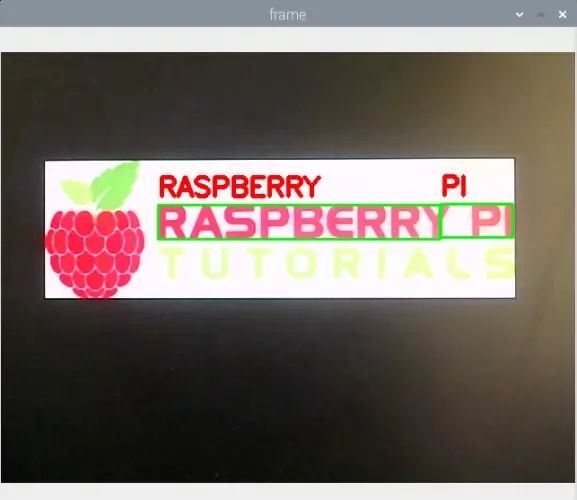
Text Recognition in Other Languages
tesseract --list-langssudo apt-get install tesseract-ocr-[lang]d = pytesseract.image_to_data(img, lang='eng')Conclusion
If you want to consult about Raspberry Pi standard products and industrial products, feel free to contact us~



We will update regularly~
Follow Raspberry Pi developers~
Learn more about Raspberry Pi related content~